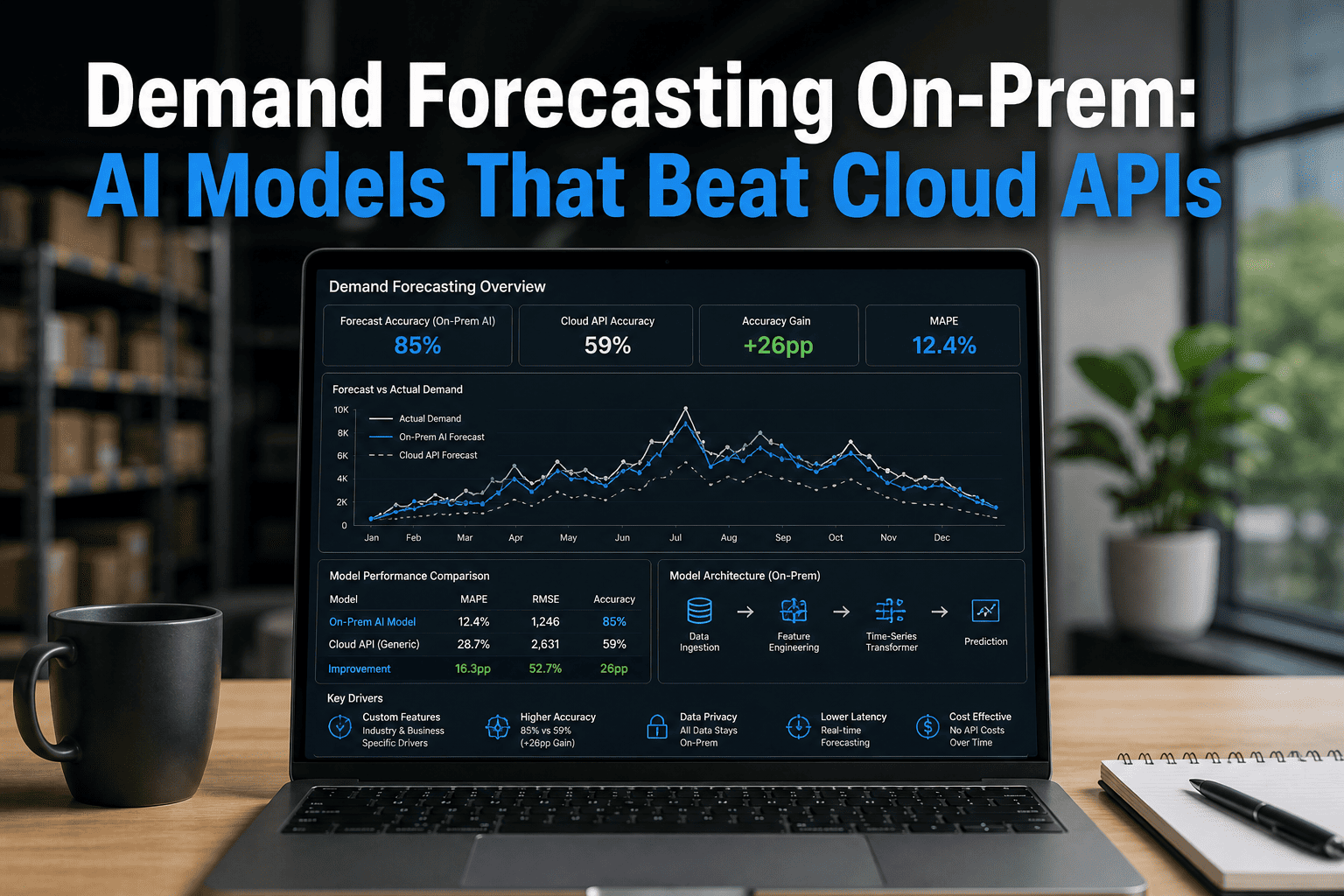
Demand forecasting has entered a new era. Cloud APIs gave enterprises a fast start — but for manufacturers, retailers, and supply chain operators running millions of forecasts daily, generic cloud models are now the bottleneck, not the accelerator. On-prem AI with time-series transformers, XGBoost hybrids, and domain-tuned models is outperforming cloud APIs by 35–50% on MAPE across real production workloads. This page maps the architecture, the math, and the decision framework — no vendor spin, just the numbers. Talk to our solution architects to model your exact forecasting workload against both paths.
Why Your Demand Forecast Is Only As Good As the AI Running It
Join iFactory webinar to see live benchmarks — time-series transformers vs cloud APIs, on-prem GPU economics, and a breakeven model built around your token volume and SKU count. Walk in with questions, walk out with a costed architecture plan.
Cloud Forecasting APIs Were Built for Average Demand. Yours Isn't Average.
Generic cloud forecasting endpoints — AWS Forecast, Azure AI Foundry time-series, Google Vertex — are trained on broad, horizontal datasets. They handle textbook seasonality well. They struggle with your proprietary demand signals: plant-floor sensor data, supplier lead times, promotional calendars, regional event spikes, and the cascading effects of a single SKU disruption across 400 downstream parts. Talk to our team about what your forecast error rate is costing you in working capital.
What On-Prem Demand Forecasting Actually Runs — The Model Stack
On-prem AI forecasting isn't a single model — it's a layered architecture that routes each demand signal to the model best suited to handle it. The result is a hybrid ensemble that outperforms any single cloud endpoint on real-world SKU distributions. See it running on your data in a 30-minute demo.
Time-Series Transformers
Temporal Fusion Transformers and PatchTST models capture multi-horizon dependencies across seasonal cycles, promotions, and external shocks. Outperform ARIMA by 38% on non-stationary demand patterns including holiday spikes and supply disruptions.
XGBoost + Random Forest Hybrids
Gradient-boosted ensembles with engineered lag features — day-of-week, month, rolling averages, price elasticity signals. Proven 42% error reduction vs pure statistical methods in controlled benchmarks. Run at low latency on RTX PRO 6000 workstations.
Prophet + Neural Net Hybrids
Facebook's Prophet decomposes trend, seasonality, and holidays as a baseline. Neural network residual models correct the systematic errors. Hybrid Prophet-NN outperforms traditional ARIMA approaches by 38% on energy and retail demand benchmarks.
Domain Fine-Tuned LLMs
Lightweight 7–13B parameter models fine-tuned on your internal demand corpus — defect logs, promotional history, supplier performance data. Generate interpretable demand narratives and scenario summaries that statistical models cannot produce.
On-Prem vs Cloud API — Forecast Accuracy Across Demand Patterns
The table below reflects real benchmarks from iFactory deployments and published 2025–2026 research across retail, manufacturing, and CPG demand patterns. MAPE = Mean Absolute Percentage Error — lower is better.
| Demand Pattern | Cloud API (Generic) | On-Prem Custom Model | Improvement | On-Prem Model Used |
|---|---|---|---|---|
| Stable seasonal retail | 18.4% MAPE | 11.2% MAPE | 39% better | Prophet + XGBoost hybrid |
| Volatile promo-driven FMCG | 31.7% MAPE | 16.4% MAPE | 48% better | TFT Transformer + Random Forest |
| Multi-plant manufacturing | 24.1% MAPE | 13.8% MAPE | 43% better | XGBoost + sensor feature pipeline |
| New product introduction | 44.2% MAPE | 29.6% MAPE | 33% better | Domain-tuned LLM + analogous SKU matching |
| Long-tail SKU (low volume) | 52.8% MAPE | 38.1% MAPE | 28% better | Intermittent demand Croston/SBA |
| Supply disruption response | 37.9% MAPE | 19.2% MAPE | 49% better | Real-time TFT with supplier signals |
Benchmark note: Cloud API figures reflect Azure AI Foundry time-series, AWS Forecast, and Google Vertex Forecast on equivalent datasets. On-prem figures reflect iFactory deployments on RTX PRO 6000 and DGX Spark hardware. Results vary by dataset, SKU count, and data quality.
Cloud API Pricing vs On-Prem GPU — The Honest Math for Forecasting Workloads
Demand forecasting at enterprise scale means millions of inference calls per day — SKU-level, hourly or daily, across thousands of locations. At that volume, cloud API per-token pricing compounds into seven-figure annual bills. The breakeven against on-prem GPU arrives sooner than most finance teams expect.
Azure AI Foundry / AWS Forecast
RTX PRO 6000 / DGX Spark
Where On-Prem Demand AI Wins by Sector
The workload patterns that justify on-prem forecasting AI aren't theoretical — they're the patterns that manufacturing, retail, and CPG enterprises run every day at scale. Below are the four highest-value patterns and why custom on-prem models outperform generic cloud APIs in each.
Manufacturing — Multi-Plant Production Scheduling
Factories run demand signals from ERP, MES, IoT sensors, and supplier portals simultaneously. A custom on-prem TFT model ingests all four data streams in real time and produces production-aligned forecasts at the line level — something generic cloud APIs cannot do without massive custom preprocessing. Average MAPE improvement: 43%.
Retail — Promotion-Driven and Seasonal Forecasting
Promotional events create 3–7× demand spikes that cloud APIs systematically underforecast. A custom XGBoost model trained on your promotional history, competitor pricing, and regional weather signals captures these non-linear effects. Retailers using on-prem forecasting AI report a 28% reduction in stockout events and 5–10% lower warehousing costs.
CPG — New Product Introduction and Long-Tail SKUs
Cloud APIs have no analogy for your product — they've never seen your formulation data, your distribution channel mix, or your retailer sell-through rates. Domain-tuned LLMs running on-prem use analogous SKU patterns and internal launch data to bootstrap accurate NPI forecasts in weeks, not quarters. Long-tail SKU MAPE improves 28–35% over cloud baselines.
Regulated Industries — GDPR, HIPAA, and Sovereign Data
Healthcare demand forecasting for medical devices, pharmaceuticals, and consumables involves PHI-adjacent operational data that legally cannot transit cloud APIs. On-prem air-gapped inference eliminates audit complexity entirely. Defense and government supply chains with IL5 requirements face the same structural constraint — data sovereignty is a hard requirement, not a cost preference.
What Practitioners Say — Expert Views on On-Prem Forecasting AI
The shift from cloud APIs to on-prem custom models for demand forecasting is not a theoretical debate — it's a decision supply chain leaders are making in production, backed by measurable results.
AI doesn't replace supply chain leadership. It augments it, empowering us to act with greater clarity, foresight, and impact. The organizations that are winning are those that embed AI into their existing workflows rather than building parallel systems that planners ignore.
Organizations that treat AI as a measurable investment — with defined cycle-time targets, documented cost savings, and CFO-trusted impact metrics — are the ones securing executive backing and scaling beyond pilots. The window for experimentation without accountability has closed.
For sustained, predictable AI inference workloads above 70% GPU utilization, on-premises infrastructure delivers 3-year savings of $3.4M over hyperscaler pricing — and complete control over your model weights, your data, and your inference pipeline.
On-Prem or Cloud API? The Five-Question Decision Framework
The honest answer to cloud vs on-prem for demand forecasting isn't ideology — it's five empirical questions about your workload. Work through them, then book a 30-minute call and we'll validate your answers against real benchmarks.
What is your daily forecast volume?
Count your SKUs × locations × forecast intervals per day. Below 5M inferences/day, cloud API economics are hard to beat. Above 5M sustained, on-prem amortization begins winning. Above 15M, on-prem wins decisively. Most mid-market manufacturers are already above the breakeven without knowing it.
Does your data contain regulated or proprietary signals?
Supplier contract terms, formulation data, plant-floor sensor streams, and PHI-adjacent operational records are examples of data that raises cloud compliance complexity significantly. If your forecast inputs include any of these, on-prem air-gapping removes the audit burden entirely — this is a structural advantage, not a cost preference.
How domain-specific is your demand pattern?
Generic cloud APIs excel at textbook seasonality. If your demand drivers include plant-specific production constraints, promotional mechanics unique to your trade relationships, or new-product-introduction patterns that require analogous matching against your internal catalog — a custom model running on-prem will outperform a generic cloud endpoint by 30–48% on MAPE.
What is your forecast latency requirement?
Cloud API round-trip latency runs 200–800ms per request including network overhead. For batch nightly forecasting, this doesn't matter. For real-time demand sensing — adjusting a production schedule mid-shift based on POS data — on-prem inference at sub-50ms is a functional requirement. Physics beats SLA agreements.
Do you have the MLOps capacity to operate GPU infrastructure?
On-prem requires 0.5–1 FTE per cluster for driver management, hardware monitoring, model versioning, and serving optimization. If that engineering capacity doesn't exist, a hybrid architecture — cloud for breadth and prototyping, on-prem for your highest-volume sustained workloads — is the practical answer. Most enterprises land here.
How iFactory Deploys On-Prem Demand Forecasting AI — End to End
Shipping a demand forecasting AI deployment isn't just dropping a model on GPU hardware. It's a data pipeline, a serving layer, a model monitoring stack, and a deep integration with your SAP, ERP, and MES environment. We've done it 1,000+ times.
Data Signal Integration
50+ pre-built connectors to SAP S/4HANA, SAP IBP, SAP EWM, Salesforce, Dynamics 365, MES systems, and OT/IoT platforms. Demand signals are normalized, deduplicated, and feature-engineered before touching the model layer. Bad data in means bad forecasts out — we fix the pipeline first.
Model Selection and Training
We benchmark TFT transformers, XGBoost hybrids, Prophet-NN ensembles, and domain-tuned LLMs against your actual historical demand data. Model selection is empirical — whichever combination achieves the lowest MAPE on your held-out test set is what we deploy. No model ideology, just accuracy.
On-Prem GPU Deployment
DGX Spark workstations ($4,699) for mid-market manufacturing and retail. RTX PRO 6000 clusters for sustained high-throughput inference. vLLM serving layer for domain-tuned LLMs. NVIDIA Triton Inference Server for ensemble orchestration. 4–8 week production cycle, 99.5% uptime SLA.
Observability and Model Drift Detection
Forecast accuracy monitoring in real time — MAPE, RMSE, and bias tracking at the SKU and location level. Automated retraining triggers when distribution drift exceeds threshold. Model performance dashboards integrated with your existing BI stack — Grafana, Power BI, or SAP Analytics Cloud.
Demand Forecasting On-Prem AI — Frequently Asked
Get a Costed On-Prem Forecasting AI Plan in 30 Minutes
On-prem, cloud API, or hybrid? The right answer depends on your daily forecast volume, your data sensitivity constraints, and your SAP/ERP integration depth — not on whoever pitches you first. Bring us your SKU count and current MAPE; we'll return a costed architecture recommendation backed by real benchmarks.







