
3 min read Most plants track OEE, but most plants cannot tell you exactly where the 40 to 60 percent of planned production time goes. The Six Big Losses framework — developed by the Japan Institute of Plant Maintenance as part of Total Productive Maintenance — provides the diagnostic precision that a single OEE number cannot. It maps every efficiency loss to one of six categories across the three OEE pillars, and each category demands a different countermeasure. Applying the same solution to a breakdown and a minor stoppage is like treating a fracture and a fever with the same prescription. This guide diagnoses each of the six losses, documents the typical OEE points each one consumes, and prescribes the specific treatment that eliminates it.
iFactory Categorizes Every Loss Minute Automatically — No Manual Entry Required
iFactory connects directly to your PLCs to capture downtime events, cycle time deviations, micro-stops, and defect counts — then maps every loss to the Six Big Losses framework with zero operator input. Book a demo to see your plant's loss profile.
OEE measures three factors. Each factor captures a different type of loss. Availability measures time loss — when the machine should be running but is not. Performance measures speed loss — when the machine is running but slower than designed. Quality measures yield loss — when the machine produces output that cannot be sold. The six losses distribute across these three factors, and every manufacturing facility experiences all six. The question is not whether they exist in your plant, but how many OEE points each one is consuming undetected.
The distribution varies by industry, but a consistent pattern emerges across discrete and process manufacturing. The chart below shows average OEE point impact per loss category based on MESA International and Lean Enterprise Institute data across 500+ plants.
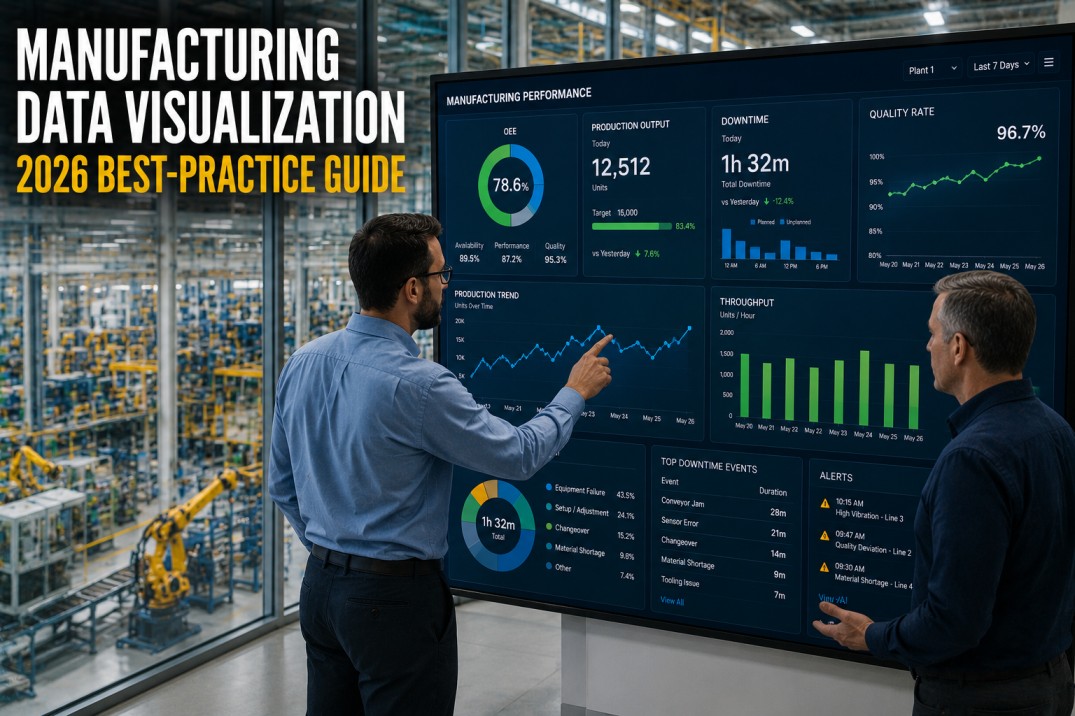
Each loss card below follows the same diagnostic format: a description of how the loss manifests on the plant floor, the typical OEE points it consumes, the root cause mechanism, a data-backed countermeasure, and how iFactory detects and eliminates it. Use these as a reference when auditing your own production lines.
Equipment Failure
Setup and Adjustments
Idling and Minor Stops
Reduced Speed
Process Defects
Startup Rejects
iFactory Maps Your Six Big Losses Automatically — From PLC Data to Pareto Report in One Click
No manual data entry. No spreadsheet analysis. iFactory connects to your existing PLCs and generates a complete Six Big Losses breakdown by shift, line, product, and time period. Book a demo to see what your plant is losing to each category.
Not all six losses deserve equal attention. The matrix below ranks them by two factors: the OEE points they typically consume and the effort required to reduce them. Losses in the top-right quadrant — high impact, manageable effort — should be your first target. Losses in the bottom-left may be better addressed after quick wins are captured.
Use the scorecard below to evaluate where your plant stands on each loss category. For each statement, rate your plant 0 (not addressed), 1 (partially addressed), or 2 (fully addressed). A score below 6 indicates significant undetected losses. Between 6 and 9 indicates opportunity for targeted improvement. Above 9 indicates mature loss management.
iFactory Generates a Complete Six Big Losses Analysis from Your Existing PLC Data — See Results in Days, Not Months
Book a demo and we will connect iFactory to one of your production lines to generate a live Six Big Losses breakdown, including OEE point impact per category, loss trend analysis, and prioritized recommendations.
What is the difference between a minor stop and a breakdown?
The threshold is typically 5 minutes. Any stop under 5 minutes that is resolved by the operator without calling maintenance is classified as a minor stop (L3, Performance loss). Any stop over 5 minutes that requires maintenance intervention is classified as a breakdown or equipment failure (L1, Availability loss). The exact threshold can be adjusted per plant, but consistency is critical — the same stop duration should always map to the same loss category to enable accurate trending and comparison across shifts and lines.
Which of the six big losses has the highest financial impact?
Equipment failures (L1) have the highest absolute financial impact because they halt production entirely and trigger emergency maintenance costs at 3–5x planned repair rates. However, process defects (L5) have the highest cost per unit because each defective part consumes raw material, machine time, energy, and labor while producing zero saleable output. A single defect event may cost more per minute than a breakdown, but breakdowns typically last longer. The highest total cost loss category varies by plant; the Pareto analysis of your specific loss data will determine your priority.
Can the six big losses apply to continuous process manufacturing?
Yes. The framework was originally developed for discrete manufacturing but applies equally to continuous and batch processes with minor terminology adjustments. In continuous processing, equipment failures map to unscheduled maintenance events, setup losses map to product grade transitions, minor stops map to process disturbances that cause off-spec production, reduced speed maps to turndown operation, process defects map to off-spec product, and startup rejects map to post-turnaround stabilization losses. The categories and countermeasures remain valid across all manufacturing types.
How do I calculate the OEE point impact of each loss?
Each loss category impacts a different OEE factor. For L1 and L2, calculate the total downtime minutes per shift divided by planned production time to determine the Availability impact. For L3 and L4, calculate the actual production rate minus the ideal rate, then divide by the ideal rate to determine the Performance impact. For L5 and L6, divide total defective units by total units produced to determine the Quality impact. Multiply each factor to derive the OEE point contribution of each loss. Manual calculation is time-intensive; most plants automate this through an analytics platform like iFactory that computes per-loss OEE impact automatically from PLC data.

.png)




