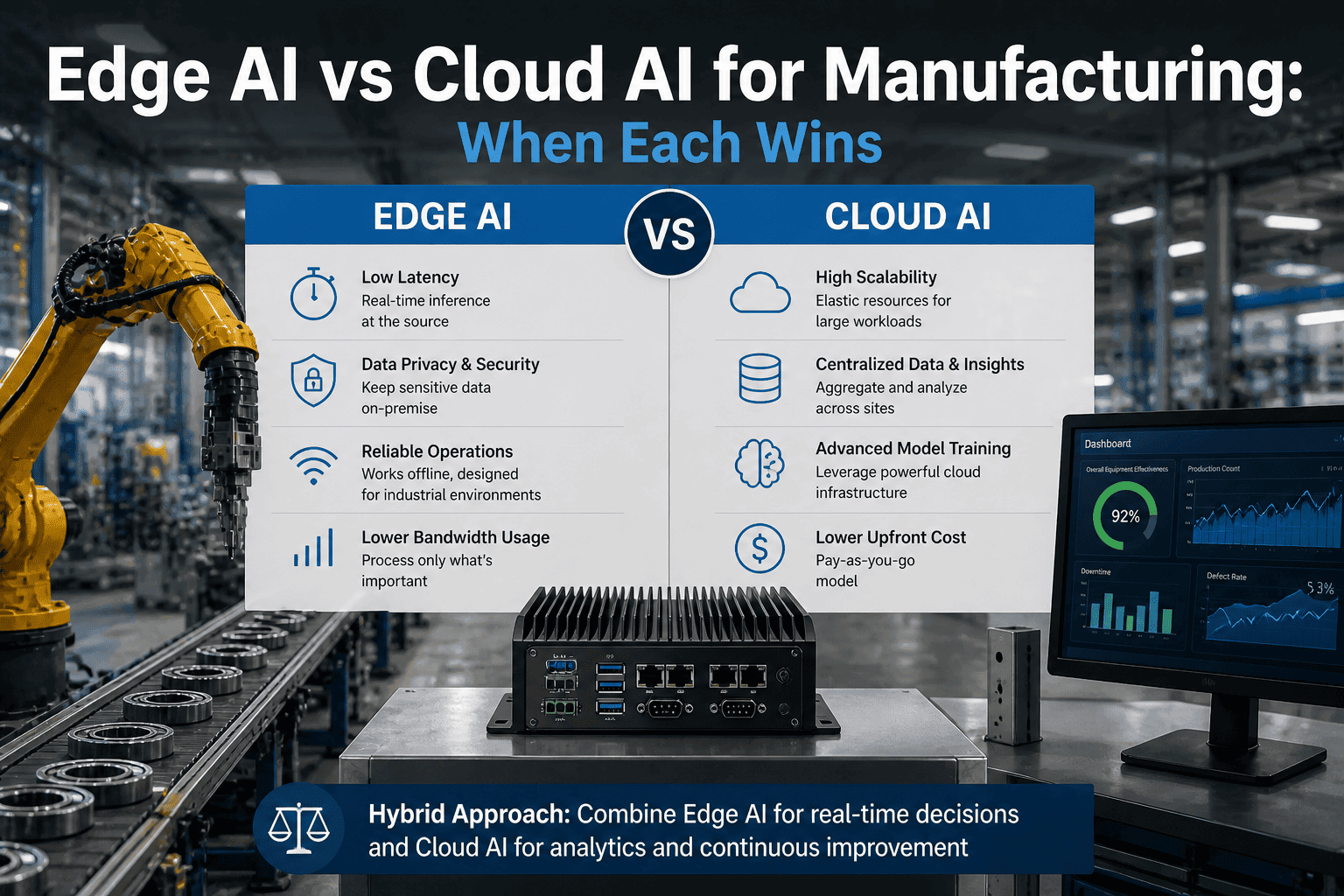
Manufacturers are increasingly choosing between Edge AI and Cloud AI based on latency, data security, and operational reliability. Edge AI processes data directly on factory-floor devices or edge GPUs, enabling real-time decision-making for applications like machine monitoring, computer vision inspection, and predictive maintenance where milliseconds matter. In contrast, Cloud AI is ideal for large-scale analytics, model training, and cross-site data aggregation where latency is less critical. Modern factories often adopt a hybrid architecture, using edge systems for immediate inference and control while sending aggregated data to the cloud for deeper analysis and continuous model improvement. This balance allows manufacturers to achieve low-latency automation, secure OT/IT integration, and scalable AI deployment across industrial operations.
Upcoming iFactory Ai Live Webinar: Edge AI vs Cloud AI for Manufacturing — Map Your Architecture
Join the iFactory team at SAP Sapphire Orlando to model your exact factory AI scenario — edge GPU inference, cloud AI, or hybrid routed by workload. Bring your latency targets and OT architecture; walk out with a defensible 2026–2028 deployment plan.
The Decision Isn't Edge vs Cloud — It's Which Workload Belongs Where
By 2026, 80% of AI inference runs locally at the edge according to industry projections — not because cloud AI failed, but because factory floors have latency requirements, OT isolation constraints, and data sovereignty rules that physics and policy make non-negotiable. Cloud AI processes data with 1–2 second round-trip delays. Edge AI delivers decisions in single-digit milliseconds. For a defect detection camera running at 120 frames per second, that gap is the difference between catching a flaw and shipping scrap. The honest answer isn't ideology — it's matching the workload to the architecture that actually works. Our architects model this against your plant's specifics in 24–48 hours.
Seven Factory Workloads — Edge Wins, Cloud Wins, Hybrid Wins
Every architecture debate collapses to one question: what response time is acceptable, and can the data leave the facility? Below are the seven workload patterns we see most in industrial AI deployments, mapped to the architecture that actually wins. Book 30 minutes to validate against your specific plant environment.
Machine Vision Quality Inspection
Camera-based defect detection at line speed requires sub-50ms inference. Cloud round-trip latency makes this category impossible regardless of bandwidth. Edge GPUs process frames locally and trigger reject mechanisms before the part leaves the inspection station.
Fleet-Wide Predictive Maintenance Modeling
Training predictive failure models across hundreds of assets and multiple sites requires compute depth and cross-site data aggregation that edge nodes cannot match. Cloud handles the training; edge handles the real-time inference of the resulting deployed model.
OT-Isolated Plant Floor Inference
Operational technology networks are deliberately air-gapped from corporate IT for safety and security. Cloud AI is architecturally excluded. Edge inference runs inside the OT boundary without requiring backhaul, so network segmentation and production continuity are preserved simultaneously.
Multi-Site Demand Forecasting and Planning
Supply chain optimization, production scheduling, and demand forecasting aggregate data across regions and ERP systems. Latency is measured in hours, not milliseconds. Cloud AI's compute depth and connectivity to SAP S/4HANA, Salesforce, and logistics platforms makes it the right layer for this workload.
Proprietary Process Data — Sovereignty Requirements
Chemical formulations, semiconductor fabrication parameters, and aerospace process tolerances are trade secrets. Sending them to a cloud provider that also serves competitors is a business risk, not just a compliance issue. Edge AI keeps proprietary process intelligence on your hardware, behind your perimeter.
Bursty or Seasonal Production Analytics
End-of-quarter production surges, new product introduction analytics, and audit-period reporting have unpredictable compute demand. Cloud's elastic scaling absorbs the variance without requiring permanent edge hardware that sits idle 60% of the year. Pay-as-you-go is the right model here.
Predictive Maintenance — Most Production Plants
Real-world predictive maintenance splits cleanly across layers. Edge nodes run anomaly detection in real time against individual assets. Shift-level reports run on a local server every few hours. Fleet-wide failure pattern models retrain monthly in the cloud. Three different problems running at three different speeds — not one problem looking for one answer.
The Latency Table That Decides Your Architecture
Response time requirements settle most architecture decisions before cost enters the conversation. Below is the latency tolerance map for the most common industrial AI workloads — and the ISA-95 hierarchy level where each belongs. Bring your workload list to our architects and we'll map each one in a single session.
| Workload | Latency Tolerance | ISA-95 Level | Architecture | Why |
|---|---|---|---|---|
| Machine vision defect detection | <10ms | L0–L1 | Edge GPU | Cloud round-trip physically impossible at line speed |
| Safety interlock / E-stop | <1ms | L0 | Dedicated edge | Hard real-time — no general-purpose AI model is appropriate here |
| Real-time anomaly detection (single asset) | <100ms | L1–L2 | Edge inference | OT-resident; must survive network outages autonomously |
| Shift performance reporting | Minutes | L3 | Local server or cloud | Latency allows either; data sensitivity governs the choice |
| Fleet-wide predictive maintenance | Hours to days | L4 | Cloud AI | Cross-site aggregation and model retraining require cloud compute depth |
| Demand forecasting / ERP planning | Hours | L4–L5 | Cloud AI | SAP/ERP integration and elastic compute — cloud is the natural layer |
| Model training on proprietary corpora | Days to weeks | L4–L5 | On-prem or hybrid | Data sovereignty may exclude cloud; compute depth required |
The TCO Breakpoint — When Edge Beats Cloud on Cost
Edge AI requires upfront CAPEX — typically $200K to $500K for a mid-size manufacturing plant. Cloud AI charges per inference. At low volumes, cloud wins. As inference volume scales with production, the math inverts decisively. The breakeven for most manufacturing workloads sits between 5M and 10M inferences per day.
~1M inf/day
~8M inf/day
~50M inf/day
What Industry Analysts and Plant Engineers Say in 2026
The shift is measurable. Here is what practitioners and researchers are observing in production environments this year — not projections, not vendor claims.
"Edge AI in 2026 is no longer about chasing the cloud to the machine. It is about respecting the machine's reality. The best systems keep inference local, survive outages, and produce measurable gains in throughput, quality, and energy efficiency."
"A Singapore manufacturing plant running edge AI for predictive maintenance achieved 93–95% fault-detection accuracy, a 70–75% decrease in equipment failures, and a 20–25% increase in total throughput through optimized uptime."
"The edge-vs-cloud question has a straightforward answer once the right question is being asked: not 'where should we run our AI?' but 'what does this specific workload require, and which level of the hierarchy delivers it?'"
The OT/IT Convergence Problem — Why Most Cloud-First Plans Stall on the Factory Floor
90% of manufacturers are integrating IT and OT — but only 28% have a shared strategy, according to Orange Business research. The gap creates a predictable failure mode: cloud AI architectures designed by IT teams that stop working at the OT boundary. Here is where the boundary actually sits and what it means for your AI deployment.
Four Things a Resilient Edge AI System Does That Cloud Cannot
Industrial networks are not utility-grade internet. They are segmented, deliberately isolated, and subject to maintenance windows. A cloud-dependent AI architecture that assumes persistent connectivity is a liability on the factory floor, not an asset.
Keeps making local decisions when the cloud is unavailable
Edge inference runs on local hardware. A WAN outage, network segmentation event, or planned maintenance window does not interrupt production. The model keeps running. The line keeps moving.
Buffers events locally so no production data is lost
Edge nodes store event logs, anomaly records, and inspection results locally during connectivity gaps. When the connection restores, the data synchronizes upstream without gaps in the audit trail.
Synchronizes with cloud analytics when connectivity returns
The hybrid pattern — filter and decide locally, forward summaries and anomalies to cloud — is called "filter local, analyze central." It trims bandwidth noise while preserving strategic insight for fleet-wide model improvement.
Degrades gracefully rather than failing loudly and expensively
A well-designed edge AI system has defined fallback behaviors — default accept, conservative reject, operator alert — so that a model failure or connectivity loss produces a controlled operational response, not a line stoppage.
Why iFactory Is the Right Partner Across the OT/IT Stack
Most cloud vendors design from L5 down and stop at the IT/OT boundary. Most hardware vendors ship the box and leave. iFactory has delivered 1,000+ industrial AI deployments across every ISA-95 level — from plant-floor edge GPU inference to S/4HANA cloud integration. Talk to our solution architects and get a recommendation backed by real production data.
Vendor-Neutral Architecture Assessment
We model edge GPU, cloud AI, and hybrid combinations against your actual workload — latency targets, inference volume, OT constraints, and data residency. The recommendation is whichever architecture wins, not whichever one we sell more of.
Full-Stack Edge Deployment
If edge wins, we ship the entire stack — hardware selection, model optimization for on-device inference, MLOps pipeline, observability, and OT network integration. Production-ready in 4–8 weeks with a 99.5% uptime SLA.
SAP, MES & ERP Integration
50+ pre-built connectors for SAP S/4HANA, MES, PLM, and industrial OT systems. Whether your AI runs at the edge or in the cloud, it reads and writes to your real business data from day one — not after a six-month integration project.
Sovereign and Regulated Environments
Defense IL5, healthcare PHI, EU GDPR, financial trade secrets. We have shipped regulated AI in air-gapped facilities, behind OT firewalls, and across multi-jurisdiction residency boundaries. Audit-ready architecture from day one.
Lifecycle Continuity — 3 to 5 Year Partnership
Models drift. Hardware refreshes. Edge GPU generations transition. We do not ship and disappear — our engineers stay engaged through the full deployment lifecycle, including model retraining, hardware upgrades, and OT environment changes.
Hybrid Routing Architecture
For workloads that split across layers — local anomaly detection at L1, shift reporting at L3, fleet analytics at L5 — we build the orchestration layer that routes each inference to the correct tier. Application code does not change; the architecture absorbs the complexity.
Edge AI vs Cloud AI Manufacturing — Frequently Asked
Get a Costed Edge vs Cloud Architecture in 30 Minutes
Edge, cloud, or hybrid — the right answer depends on your latency targets, OT network topology, inference volume, and data residency constraints. Bring us your plant's scenario; we will model the TCO, map the ISA-95 hierarchy, and give you a defensible recommendation backed by 1,000+ industrial AI deployments.







