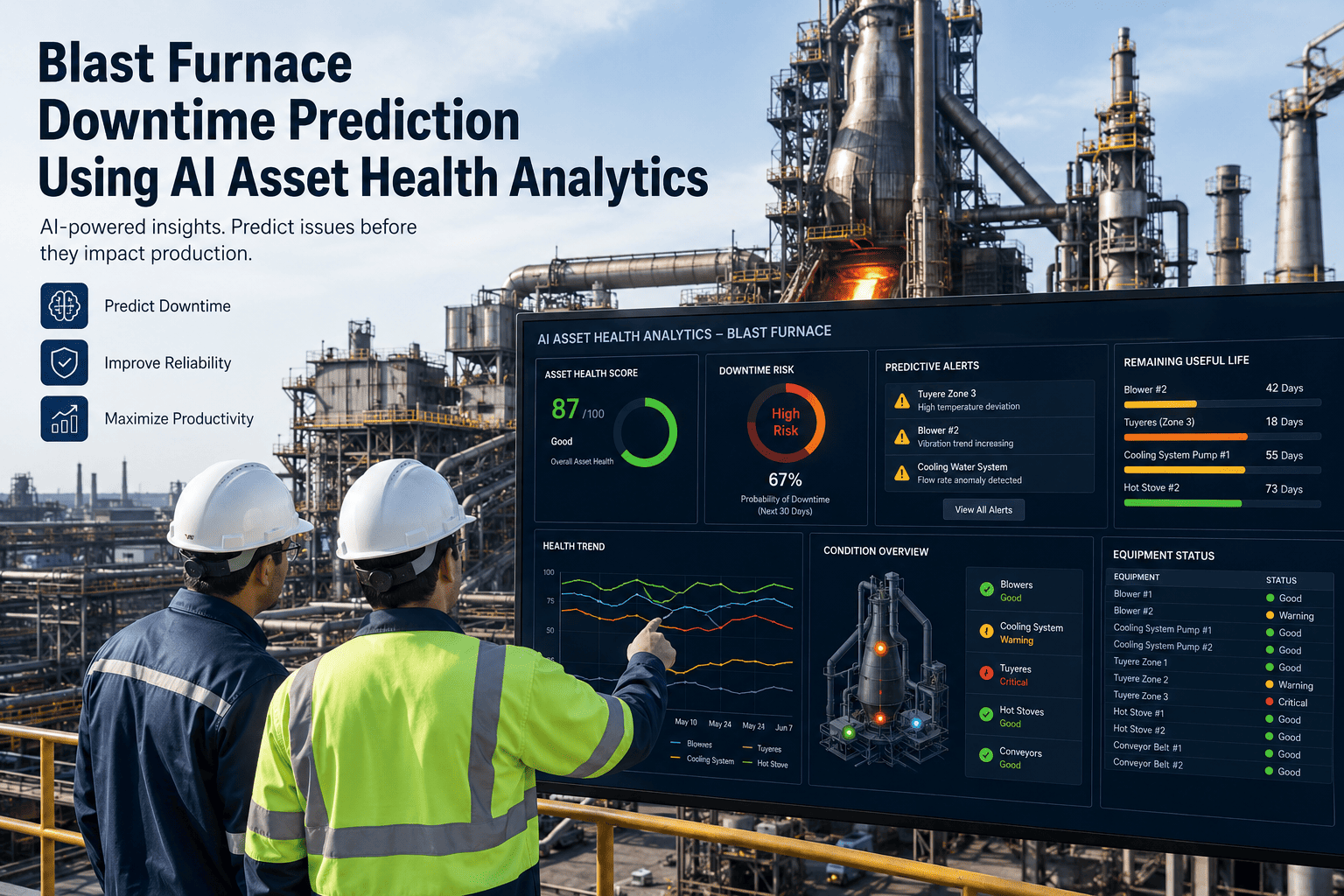
Rotating equipment carries the highest failure risk and the highest cost of any asset class in oil and gas, and a single unplanned trip on a compressor or pump can idle a production unit for hours at a cost that runs into six figures per hour. Most reliability teams still schedule bearing changes, seal replacements, and vibration checks on a fixed calendar, which means healthy machines get serviced too often while a degrading unit can fail between rounds. AI predictive maintenance reads the actual vibration, temperature, and current signature of every pump, compressor, and turbine on the asset list, and flags the ones that are actually drifting toward failure weeks before a trip occurs. Reliability engineers evaluating this shift for their own fleet can book a demo to see live asset health scoring on rotating equipment.
OIL & GAS · PREDICTIVE MAINTENANCE
Catch Rotating Equipment Failures Weeks Before They Happen
AI-driven predictive maintenance reads vibration, temperature, and current signatures across every pump, compressor, and turbine on your fleet, turning emergency trips into planned, scheduled work.
What Reactive Maintenance Actually Costs a Facility
Median unplanned downtime across heavy process industries runs near six figures an hour, and oil and gas facilities routinely sit at the higher end of that range once deferred production, emergency callouts, and off-spec product are counted together. The cost rarely shows up as one line item, which is exactly why fixed-interval maintenance keeps surviving budget reviews even after it fails to catch the trip that actually happened.
$100K+
Typical cost per hour of unplanned downtime on critical rotating equipment
52%
Share of unplanned shutdowns traced back to reactive maintenance practices
14-21
Days of advance warning typical failure signatures provide before a trip
See Your Own Fleet's Health Score
A short walkthrough shows exactly how failure signatures surface on pumps, compressors, and turbines like yours.
Prediction Windows by Asset Class
Not every rotating asset behaves the same way electrically or mechanically, so the amount of advance warning a model can realistically deliver varies by equipment type. Pumps and electric drives tend to give the earliest, most reliable signals since current signature analysis is a well-established discipline, while static and pressure equipment is still an emerging category for most mid-size operators.
| Asset Class |
Typical Warning Window |
Downtime Reduction |
Deployment Maturity |
| Centrifugal Pumps |
14-21 days |
30-45% |
Production-Ready |
| Compressors |
10-18 days |
25-40% |
Production-Ready |
| Turbines |
20-30 days |
20-35% |
Production-Ready |
| Electric Drives & Motors |
15-25 days |
30-40% |
Production-Ready |
| Static & Pressure Vessels |
5-10 days |
10-20% |
Emerging |
How the Prediction Actually Gets Built
01
Continuous Signal Capture
Vibration, temperature, pressure, and motor current data streams in from existing sensors and historians, no rip-and-replace of instrumentation required.
02
Baseline Health Scoring
Each asset gets a normal operating signature learned from its own history, so alerts reflect real deviation instead of a generic threshold.
03
Failure Signature Matching
Emerging patterns are compared against known failure modes for bearings, seals, rotor bars, and windings to flag the specific fault developing.
04
Prioritized Work Order
A ranked alert routes straight to the maintenance queue with the predicted failure mode, so planners schedule the fix instead of chasing an alarm.
We used to find out a pump was failing when it tripped mid-shift, and by then it was already an emergency. Now we see the bearing signature drifting days out and put it on the next planned shutdown instead. Our unplanned trips on the fleet are down noticeably since we made that switch.
Reliability Manager, Midstream Compression Operator
Is Your Facility a Strong Fit to Start
Rotating equipment is consistently the safest and fastest place to pilot predictive maintenance, since the failure modes are well understood and the sensor stack is inexpensive to add where it's missing. A few operational signals point to a facility that will see results fast rather than a slow, uncertain rollout.
High Count of Pumps and Compressors
Fleets with dozens of rotating assets see the fastest payback since one avoided trip covers the pilot cost.
History of Unplanned Trips
A documented pattern of reactive repairs on specific units makes the ROI case easy to build and defend.
Existing SCADA or Historian Data
Facilities already streaming pressure, flow, and temperature data integrate in weeks instead of months.
Frequently Asked Questions
Turn Emergency Trips Into Planned Work
Get a walkthrough of predictive maintenance running against your own pumps, compressors, and turbines.