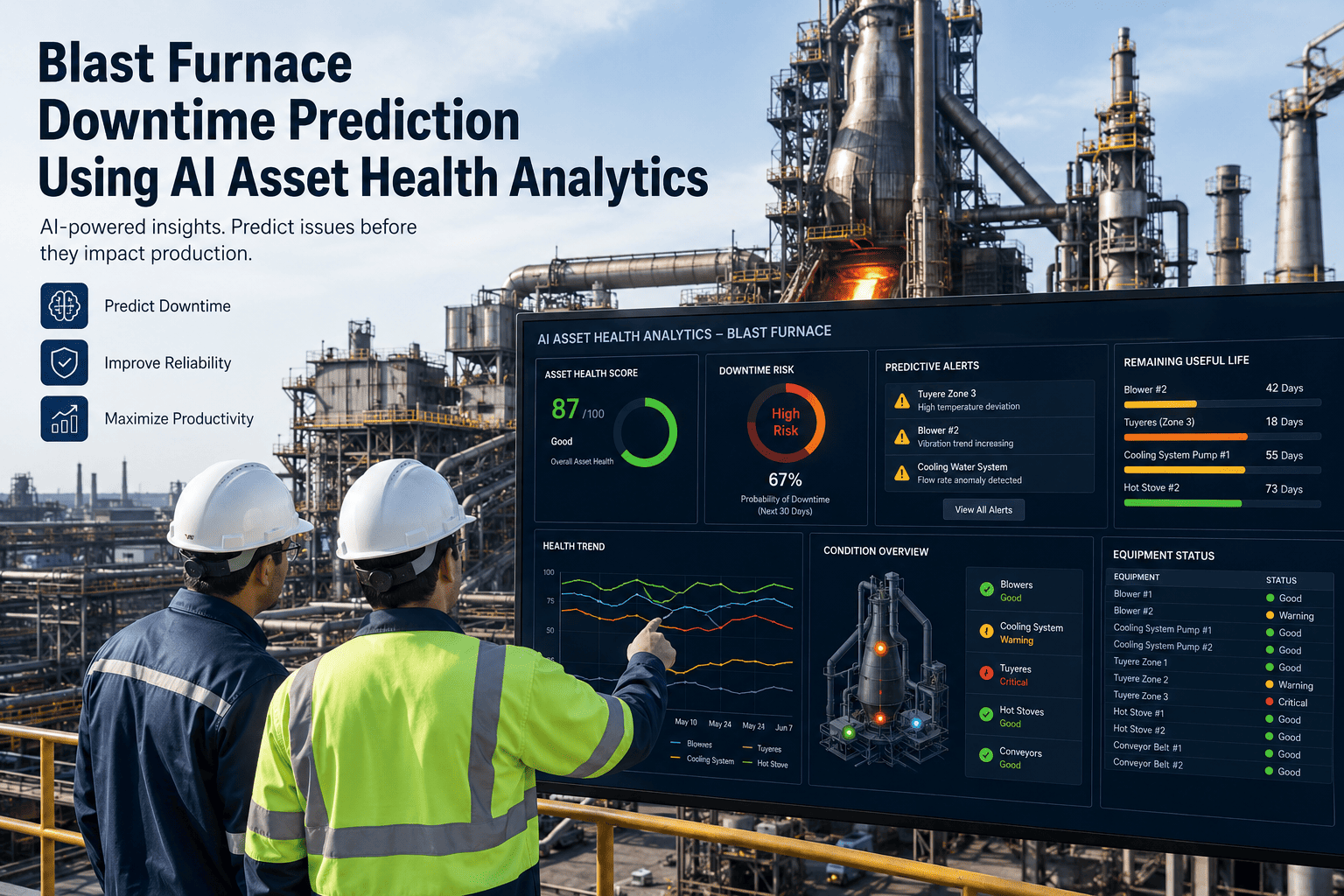
A blast furnace does not stop on a convenient schedule. When a critical component like a tuyere, cooling stave, or hot blast valve starts to fail, the furnace itself often has to be slowed or taken offline entirely, and every hour of that stoppage carries a cost that dwarfs almost any other unplanned event in a steel plant. Furnace managers have traditionally relied on scheduled inspections and operator experience to catch problems early, but by the time a visible warning sign appears, the underlying degradation has usually been building for weeks. AI asset health analytics changes the timeline by continuously reading temperature, pressure, and vibration data across the furnace and its auxiliary systems, spotting the early drift patterns that precede a failure long before a manual inspection would catch them. Furnace and reliability managers who want to see this on their own asset data can book a demo and walk through a live prediction dashboard.
PREDICTIVE MAINTENANCE · STEEL PLANTS · 2026
Predict Blast Furnace Failures Weeks Before They Happen
AI asset health analytics watches every critical furnace system in real time, giving reliability teams weeks of warning before a failure forces an unplanned stoppage.
$500K+
Estimated cost per hour of unplanned blast furnace downtime once production loss and restart costs are included
2-8 Weeks
Typical advance warning AI models provide before a critical furnace component failure occurs
35-45%
Reduction in unplanned furnace downtime reported by plants running continuous asset health monitoring
24/7
Continuous monitoring across tuyeres, staves, and hot blast systems that periodic manual checks cannot match
Why Blast Furnace Failures Are So Costly to Get Wrong
Unlike a single piece of equipment on a production line, a blast furnace is a continuous chemical and thermal process that cannot simply be switched off and restarted the way a conveyor or a pump can. A cooling stave failure or a tuyere burn-through does not just stop production, it can risk damage to the furnace lining itself, turning a maintenance event into a multi-week reline project costing tens of millions of dollars. Furnace managers have historically managed this risk through conservative scheduled maintenance and close operator attention to process trends, but both approaches leave gaps. Scheduled maintenance replaces components on a calendar regardless of actual condition, while operator attention, however skilled, cannot process the volume of sensor data a modern furnace generates every second. AI asset health analytics closes both gaps by continuously modeling the condition of every monitored system against historical failure signatures.
Critical Failure Points AI Monitoring Watches
Not every furnace component carries the same risk, and reliability teams focus monitoring resources where failure consequences are most severe.
| Component |
Failure Mode |
Consequence if Missed |
| Tuyeres |
Burn-through from cooling water loss or blockage |
Emergency shutdown, risk to furnace lining |
| Cooling Staves |
Cracking or water leak into the furnace |
Extended repair, potential production loss |
| Hot Blast Valves |
Seal degradation or actuator failure |
Loss of blast control, forced rate reduction |
| Bosh and Hearth Refractory |
Thermal erosion beyond safe thickness |
Major reline project, months of lost production |
Reactive vs Scheduled vs AI-Predicted Maintenance
Furnace reliability strategies fall along a spectrum, and the difference in outcome between the two ends of that spectrum is significant when the asset in question is a blast furnace.
Reactive Response
Highest risk
Scheduled Inspection
Moderate risk
AI Asset Health Monitoring
Lowest risk
Relative risk of unplanned failure by maintenance strategy, based on industry reliability benchmark data
How AI Asset Health Analytics Works on a Blast Furnace
The monitoring process is designed to layer onto existing furnace instrumentation without disrupting the process itself.
1
Sensor Data Integration
Temperature, pressure, flow, and vibration data from existing furnace instrumentation feeds continuously into the monitoring platform.
2
Condition Modeling
Machine learning models compare live readings against historical failure patterns specific to tuyeres, staves, and hot blast systems.
3
Risk-Ranked Alerts
Developing issues are ranked by severity and time-to-failure estimate, so reliability teams act on the highest-risk components first.
4
Planned Intervention
Confirmed risks convert into scheduled maintenance windows, replacing emergency shutdowns with planned, controlled interventions.
PREDICTIVE MAINTENANCE · STEEL PLANTS · 2026
See Your Furnace Risk Profile in Real Time
Get a personalized walkthrough of how AI asset health analytics would apply to your furnace instrumentation and failure history.
A Rollout Plan That Respects Furnace Campaign Continuity
Furnace reliability teams cannot risk disrupting a live campaign to install new monitoring. A staged rollout builds confidence in the models before they influence real shutdown decisions.
Weeks 1-3
Instrumentation Audit
Existing sensors across tuyeres, staves, and hot blast systems are mapped, and historical failure records are gathered for model training.
Weeks 4-8
Model Training
Historical failure signatures train the prediction models, with baseline thresholds calibrated for each monitored component type.
Weeks 9-14
Shadow Monitoring
The system runs alongside existing inspection routines, with alerts validated against real furnace conditions before being trusted operationally.
Month 4+
Operational Integration
Validated alerts feed directly into maintenance planning, with continuous retraining improving accuracy as the campaign progresses.
What Reliability Managers Are Saying
A tuyere failure used to mean an emergency shutdown with almost no warning, and every one of those events put the furnace campaign at risk. Since we started monitoring cooling water flow and temperature trends continuously, we have caught developing tuyere issues weeks ahead of failure and scheduled the replacement during a planned window instead of an emergency stop. It has fundamentally changed how our reliability team plans its work.
Reliability Manager, Integrated Steel Plant
Frequently Asked Questions
PREDICTIVE MAINTENANCE · STEEL PLANTS · 2026
Ready to Stop Losing Campaigns to Surprise Failures?
Join steel plants already using AI asset health analytics to catch blast furnace failures weeks before they happen and protect campaign continuity.