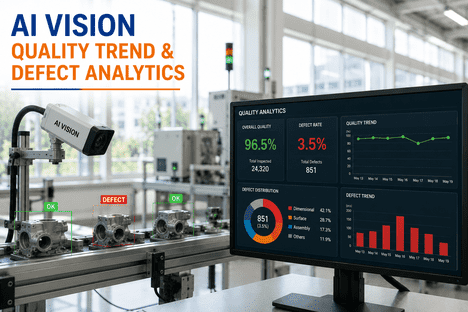
Every AI vision model that fails in production traces back to the same root cause: a training dataset that never matched what the camera would actually see on the floor. Teams spend weeks arguing about model architecture while the real bottleneck sits in the image folder — too few marginal parts, inconsistent labels, no coverage of different shifts or lighting. The good news is that modern deep learning needs far less data than most quality teams assume, provided the images and labels are built with the right method from day one. This guide walks through exactly how many images to capture, how to label them for different defect types, and how to check that your annotations are trustworthy enough to train on. If your team is stuck deciding where to start, book a demo and we will map the dataset plan to your actual defect classes.
Data Foundations
How to Collect and Label Training Images for Industrial AI Vision
The practical dataset math and labeling method behind every AI vision model that survives contact with the production floor
How Many Images Do You Actually Need?
The number of images required depends on defect complexity, not on how much data you can theoretically collect. Most production-ready models are trained on far fewer images than teams initially budget for.
50–150
Simple, high-contrast defects on a consistent part — one class
150–500
Moderate complexity defects with some surface or lighting variation
300–800
Subtle defects like hairline cracks or fine surface porosity
500–2,000
Full station dataset spanning good, marginal, and defective parts
The Dataset Composition That Actually Works
Total image count matters less than the mix. A dataset built only from perfect parts and obvious defects will fail the moment a borderline part reaches the line.
Good Parts 60%
Marginal Parts 25%
Defective Parts 15%
Good parts establish the baseline of normal variation across batches, shifts, and lighting
Marginal parts teach the model where the accept/reject line actually sits, not just the extremes
Defective parts should span every severity level, not only the most obvious failures
Choosing the Right Labeling Method
The annotation format you choose determines what the model can learn to output. Matching the method to the inspection task saves weeks of relabeling later.
Bounding Boxes
Fast to draw and ideal when you need to know a defect's location and rough size but not its exact shape. Best for scratches, dents, and missing components where a rectangle around the region is sufficient for a work order.
Fastest to label
Polygons
Traces the exact outline of irregular defects — cracks, corrosion, stains, and porosity clusters. Takes longer per image but gives pixel-level area measurement, which matters when severity is scored by defect size.
Highest precision
Classification Tags
A single label per image — pass, fail, or defect type — with no location marked. Useful for anomaly-style models where the question is simply whether the part conforms, not where the flaw sits.
Simplest to scale
Not sure which method fits your defect types? Book a demo and we will review sample images from your line before you label a single one.
The Labeling Workflow, Step by Step
Consistent labels come from a consistent process, not from a single skilled annotator working alone. Here is the sequence that keeps a dataset clean as it scales.
1
Write the Label Book First
Define every defect class in writing before anyone opens the labeling tool — what counts as cosmetic versus critical, minimum size thresholds, and edge-case examples with agreed answers.
2
Label in Small, Reviewed Batches
Annotate in batches of 50–100 images, then review before moving forward. Catching a drifting standard early is far cheaper than relabeling a finished dataset.
3
Measure Inter-Annotator Agreement
Have two annotators label the same sample set independently and compare results. Low agreement signals an ambiguous label book, not a training data problem — fix the definitions before labeling more images.
4
Collect Hard Negatives Continuously
Once the model is live, every false reject and missed defect becomes a labeled training example for the next retraining cycle — the dataset keeps improving instead of freezing at go-live.
Skip the Months of Trial-and-Error Labeling
iFactory's active learning workflow minimizes manual labeling effort while maximizing model accuracy — starting from as few as a few hundred images per defect class.
Common Dataset Mistakes That Sink Accuracy
The same handful of mistakes appear across nearly every underperforming vision model, regardless of industry or defect type.
Training only on staged lab images
A model trained on clean, evenly lit samples degrades within days of exposure to real shift-to-shift lighting and material variation on the floor.
Ignoring shift and batch coverage
Different shifts, machines, and material lots introduce visual variation the model needs to see during training, not discover for the first time in production.
Skipping the marginal cases
A dataset of only obvious good parts and obvious defects leaves the model guessing exactly where your real accept/reject boundary should sit.
Never checking annotator agreement
Inconsistent labeling between annotators quietly caps your model's ceiling accuracy no matter how much data you collect afterward.
Frequently Asked Questions
Do we need thousands of images before we can start training?
No. Most production-quality models begin with a few hundred labeled images per defect class rather than thousands. Transfer learning from models already trained on large industrial defect libraries means your dataset only needs to teach the model what is specific to your part and your defects, not visual concepts from scratch. Coverage of real production variation matters far more than raw volume. If you want a specific number for your part type,
book a demo and bring a handful of sample images.
Should we label every image ourselves or use an outside labeling service?
Either can work, but in-house labeling by people who understand your product usually produces more consistent results for subtle or cosmetic defect judgment calls. Outside services scale faster for large volumes of straightforward defects. The critical factor either way is a clear, written label book and a regular check of agreement between whoever is labeling, so standards do not drift as the dataset grows.
What is inter-annotator agreement and why does it matter this much?
Inter-annotator agreement measures how often two people labeling the same images reach the same conclusion. Low agreement means your defect definitions are ambiguous, and a model trained on inconsistent labels will learn an inconsistent, blurred concept of what counts as a defect. High agreement is a leading indicator of how accurate your finished model can realistically become, well before training even begins.
Do bounding boxes or polygons produce a more accurate model?
Neither is universally more accurate — the right choice depends on the inspection question you need answered. Bounding boxes are faster to produce and sufficient when location and rough size are enough to route a part for rework. Polygons take longer per image but give pixel-level shape and area, which matters when severity scoring depends on exact defect size, such as porosity or corrosion coverage.
How do we keep the dataset current after the model goes live?
Every false reject and missed defect the model produces after go-live becomes a candidate training example. Reviewing and labeling that feedback continuously — often called hard negative mining — keeps the model adapting to real drift in materials, lighting, and new defect types without a full dataset rebuild. Most teams fold this into a routine retraining cycle. Reach out to
support if you want help setting up that ongoing pipeline.
Build a Dataset That Actually Holds Up in Production
Bring your part samples and defect history — we will map exactly how many images you need, which labeling method fits, and how fast you can reach a validated model.