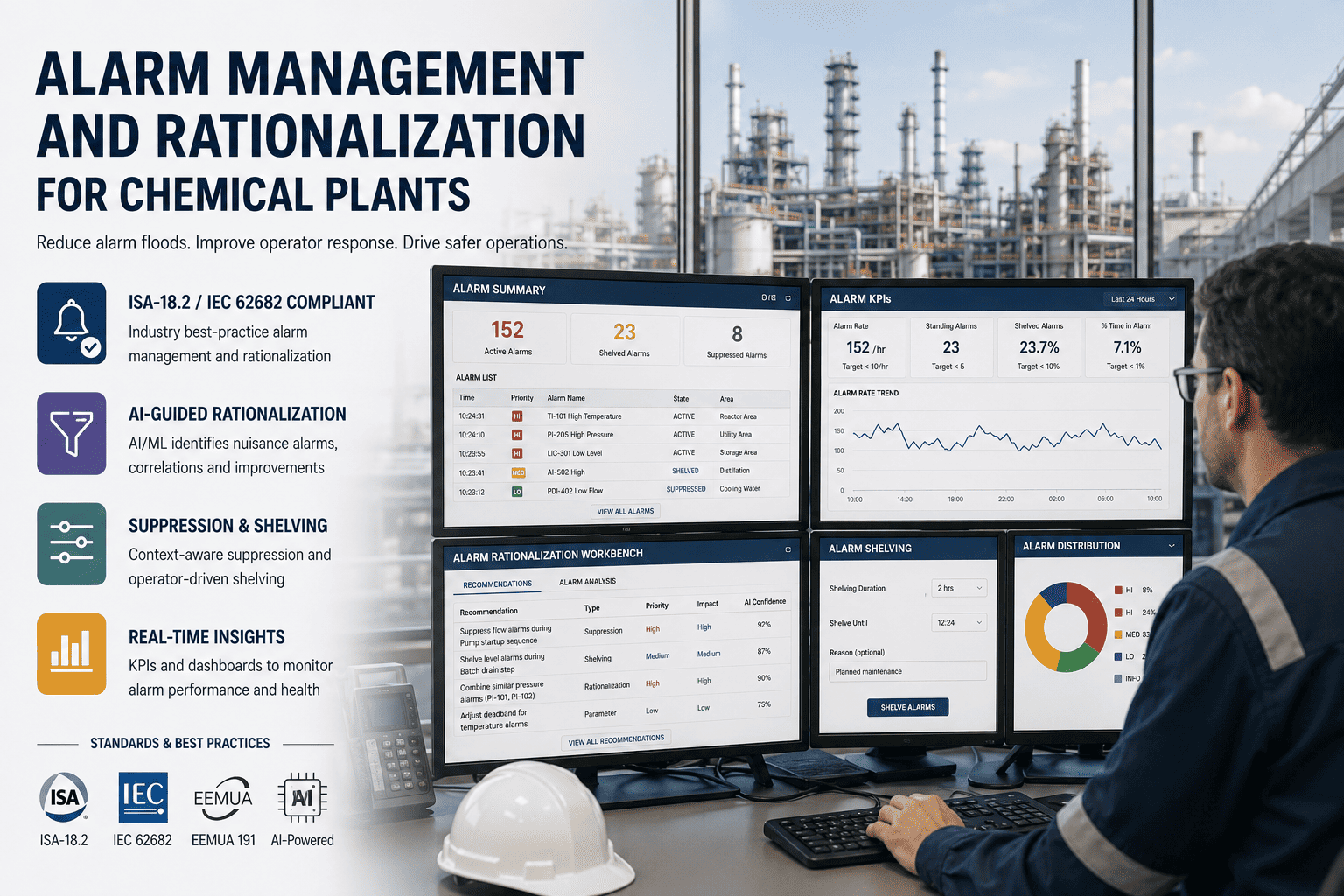
At 04:12 on a Thursday at a specialty chemicals plant, a routine compressor trip generated 247 alarms in seven minutes across the control room HMI. The lead operator silenced the panel, started the SOP for the trip, and worked through the cascade. Buried at position 134 in the alarm list — invisible by then — was a reactor jacket cooling alarm that took 41 minutes to acknowledge. The batch was salvaged but the post-incident review made one thing clear: the alarm system had stopped functioning as a warning system years ago. It was a noise system, and the operator was the filter. This page is for control room leads who already know the symptom and need the playbook — ISA-18.2 / IEC 62682 / EEMUA 191 rationalization with modern AI guidance on top.
Alarm Management and Rationalization for Chemical Plants — ISA-18.2, IEC 62682, EEMUA 191 with AI Guidance
Rationalization is not a one-time workshop and shelving is not an excuse for ignoring problems. Standards-compliant alarm management is an 11-stage lifecycle. AI guidance — predictive suppression, adaptive shelving, dynamic prioritization — is the operating layer that keeps the rationalized system from drifting back to flood within eighteen months.
Typical Chemical Plant vs EEMUA 191 — The Alarm Performance Gap
Most chemical plants discover the gap between their actual alarm performance and the EEMUA / ISA / IEC benchmarks only after an incident review. The numbers below are typical of a 100-loop chemical plant operating without a current rationalization. Compare against your own monthly alarm report — the picture is rarely flattering, and the gap is the budget for improvement.
| KPI | Typical un-rationalized site | EEMUA 191 / ISA-18.2 target | Why it matters in a chemical plant |
|---|---|---|---|
| Average alarm rate (steady state) | 30–150 per hour per operator | < 6 per hour (≈ 1 per 10 min) | Above 12/hr operators stop reading alarms — they only react to the loudest |
| Peak alarm rate (upset) | 100–400 alarms in 10 min | < 10 alarms in 10 min | During an upset is exactly when a flood is most dangerous — the critical alarm is buried |
| Standing alarms (active > 1 hr) | 20–80 at any time | < 5 per operator | Each one trains the operator that "alarm" does not mean "act now" |
| Chattering alarms | 10–30 active | 0 | Repeated activation of the same tag — first thing AI guidance suppresses |
| Stale alarms (> 24 hr) | 5–20 | 0 | A 36-hour active alarm is not an alarm — it is a permanent status badge |
| Priority distribution H / M / L | 30 / 40 / 30 (priority inflation) | 5 / 15 / 80 | When everything is "High," priority has stopped communicating urgency |
| Bad actor contribution (top 10) | 40–60% of total alarm load | < 5% from top 10 tags | A handful of misconfigured tags creates the majority of the noise |
| Operator response time on High alarms | 10–45 min median | < 10 min on every High | The Buncefield and Texas City reviews both flagged delayed response inside floods |
Why this gap is not a sign of operator failure
Alarm system performance drifts downward over time without exception. Tags get added during MOC, priorities get bumped to "High" because someone insisted, suppressions get applied for one shift and never removed. Twelve to eighteen months after a clean rationalization, an un-managed system is back where it started. The gap is the structure, not the people.
Six Alarm Pathologies — What Goes Wrong, and What Fixes Each One
Six recurring failure modes account for almost all alarm-system dysfunction in chemical plants. Each has a definition under ISA-18.2 and EEMUA 191, a measurable signature in the alarm log, and a specific remediation. The fixes are the work program of a rationalization, not opinions.
Nuisance alarms
Definition: Alarms that activate without an actionable abnormal condition — sensor noise, transient process variation, calibration drift.
Detection: High activation count, no operator action recorded, no consequence on production.
Remediation: Deadband widening, on-delay timer (typically 3–10 seconds), or removal during rationalization workshop.
Chattering alarms
Definition: Same tag activates and clears repeatedly in a short window — typically more than three times in a minute.
Detection: Automated reports from the alarm historian, AI guidance flags within hours.
Remediation: Hysteresis tuning, sensor inspection, or deadband adjustment. AI suppression can hold the alarm while the engineering fix is implemented.
Standing and stale alarms
Definition: Alarms active for more than one hour (standing) or more than 24 hours (stale) without operator action.
Detection: Active alarm list report — anything older than an hour belongs on the standing list.
Remediation: Shelving with documented justification and expiry, or rationalization to determine if the alarm should exist at all.
Priority inflation
Definition: A distribution where High and Medium priority dominate — typically 30 / 40 / 30 or worse — because every alarm owner believes their alarm is critical.
Detection: Priority distribution histogram on the monthly alarm report.
Remediation: Rationalization workshop assigns priority through consequence-and-time-to-respond matrix. EEMUA 191 target is 5 / 15 / 80.
Alarm flood
Definition: More than 10 alarms in 10 minutes per operator — the cognitive cliff above which operators stop reading and start silencing.
Detection: Flood report against rolling 10-minute windows, classified by triggering event.
Remediation: State-based suppression, dynamic alarm management, cause-effect consolidation — and AI predictive suppression for known cascade patterns.
Bad actor tags
Definition: A small number of tags contributing a disproportionate share of total alarm load — typically the top 10 contribute 40–60%.
Detection: Pareto of alarms by tag in the monthly report — the curve is always brutally skewed.
Remediation: Targeted engineering on the top contributors — sensor calibration, deadband, process tuning. Fastest path to a 50%+ alarm rate reduction in week one.
ISA-18.2 / IEC 62682 Lifecycle — Where Your Program Lives
ISA-18.2 (revised 2016, harmonised with IEC 62682) defines alarm management as an eleven-stage lifecycle, not a project. Most plants enter the cycle at one of three entry points — philosophy, monitoring and assessment, or audit. Knowing your entry point determines the order of operations for the next eighteen months.
Philosophy
The foundational document. Defines what an alarm is, how priorities are assigned, who owns rationalization, how shelving works. Required entry point for any new program.
Entry pointIdentification
Sources from HAZOP, LOPA, P&ID review, regulatory requirements, and existing control system tags. The candidate list before rationalization.
Rationalization
The workshop. Each alarm tested against philosophy criteria — does it have a defined operator action, a definable consequence, and time to respond? Pass means keep; fail means cut.
Detailed Design
Setpoint, deadband, on-delay, off-delay, priority, suppression logic. The engineering specification for each surviving alarm.
Implementation
DCS configuration changes through MOC. Operator training on changed alarms, philosophy walk-through, console-by-console.
Operation
Day-to-day use of the rationalized system. Operator response, shift handover protocols, alarm response procedures available at the console.
Maintenance
Instrument calibration, sensor health checks, deadband re-tuning. The engineering activities that keep alarms accurate.
Monitoring & Assessment
Monthly KPI reports against benchmarks, bad-actor identification, drift detection. Entry point for sites that already have a philosophy but no operational control.
Entry pointManagement of Change
Every alarm change — new, modified, removed — flows through documented MOC referencing the philosophy. Prevents the slow drift back to flood.
Audit
Periodic — typically annual — review of the whole program against the philosophy. Entry point for sites that need a fresh independent assessment before committing to a full re-rationalization.
Entry pointContinuous Improvement
The feedback loop — assessment findings drive the next round of rationalization, philosophy updates, and KPI threshold tuning. Without this, the cycle stops being a cycle.
Anatomy of a Rationalization Session — What Actually Happens in the Room
Rationalization is the highest-leverage stage in the lifecycle. A good workshop reduces alarm count by 30–60% before any AI or suppression logic is applied. The structure below is what works in chemical plant rationalizations — process engineer, operations, instrumentation, and safety in one room, walking the alarm list against the philosophy.
Source the candidate list
Pull every active alarm tag from the DCS — including suppressed and shelved tags. Add HAZOP and LOPA recommendations not yet implemented. Typical specialty-chemical unit yields 800–2,500 candidate alarms.
Apply the three-question philosophy test
For each candidate, ask: (1) Is there a defined operator action that is different from what they would do without the alarm? (2) Is there a definable consequence if no action is taken? (3) Is there sufficient time to take the action? Three "yes" answers means it is an alarm. Anything else is removed or downgraded to an event log.
Assign priority via the consequence matrix
Priority is a function of consequence severity and time available to respond — not how strongly the alarm owner argues for "High." A documented matrix forces consistent application. The target distribution is roughly 5% High / 15% Medium / 80% Low.
Document the alarm response procedure
For every surviving alarm, capture the cause, consequence, and operator action in a structured master alarm database. This becomes the operator's alarm response procedure (ARP), available at the console when the alarm fires.
Specify engineering settings
Setpoint, deadband, on-delay, off-delay, suppression logic, classification (BPCS vs SIS, regulatory vs operational). The output of this step feeds the detailed design and MOC.
Consolidate cascade and effect alarms
Where multiple alarms signal a single root cause — common in compressor trips, distillation column upsets, reactor cascades — define the parent alarm and suppress the children. This is where AI guidance adds the largest gain in pre-existing systems.
What AI Guidance Adds to a Rationalized System
A rationalized alarm system without an operational AI layer drifts back to flood within twelve to eighteen months. AI guidance is not a replacement for the lifecycle — it is the operating layer that maintains it. Four capabilities matter, and they are listed in the order they typically deliver value.
Predictive suppression of known cascades
The system learns the alarm signatures of common cascades — compressor trip, column upset, reactor cooling failure — and pre-emptively suppresses the child alarms once the parent signature is detected. A 247-alarm flood becomes a 6-alarm cluster centered on the root cause.
Largest one-shot reductionAdaptive shelving with documented expiry
Operator-initiated shelving with mandatory justification, expiry timer, and supervisor approval routed automatically. AI tracks shelving patterns and flags tags that get shelved repeatedly — those go on the next rationalization candidate list.
Maintains rationalization integrityDynamic prioritization by operating state
An alarm that is "High" during normal operation may be irrelevant during startup or shutdown — and vice versa. State-based prioritization adjusts the alarm's effective priority based on the current operating mode, eliminating one of the biggest sources of nuisance noise.
Eliminates state-mismatch noisePattern-based root cause guidance
When a cluster of alarms fires, the AI surfaces the most likely root cause based on the temporal pattern, correlated process variables, and historical incident data. This is decision support, not automation — the operator still acts, but the alarm list is annotated rather than scrolled.
Decision support, not automationGet a one-month baseline against EEMUA 191
We connect non-invasive to your DCS alarm historian, run a 30-day baseline, and deliver a report against every EEMUA / ISA-18.2 KPI with bad-actor Pareto, flood analysis, and a rationalization scoping estimate. No change to the validated control system.
- Non-invasive historian connect
- 30-day KPI baseline
- Bad-actor Pareto with engineering recommendations
- Rationalization workshop scoping
- On-premise NVIDIA AI server, racked and ready
- Live in 6–12 weeks, no DCS modification
Suppression vs Shelving — When Each Applies, How Each Is Governed
Suppression and shelving are operational tools, not workarounds. ISA-18.2 defines both with specific intent, and a control room lead who knows the distinction can use them confidently. Used wrong, they become the mechanism by which the alarm system silently degrades.
Suppression
Engineered, designed, and automaticSuppression is configured during detailed design — a rule that automatically blocks an alarm under defined conditions. State-based suppression hides startup alarms during shutdown. Cascade suppression blocks downstream alarms when a parent alarm is active. AI predictive suppression learns these patterns and applies them in real time.
When to use- The alarm is meaningful in some operating states but not others
- The alarm is a known downstream effect of a parent condition
- The suppression is documented in the alarm philosophy
- The behaviour is fully automatic — no operator action required
Shelving
Operator-initiated, temporary, justifiedShelving is a temporary operator action to silence a specific alarm for a defined period, with a documented reason. It is used when an alarm is firing for a known reason — a sensor under repair, a temporary process condition — that the operator does not want to acknowledge repeatedly. Shelving is bounded by time and requires justification.
When to use- The cause is known and engineering action is already initiated
- The duration is bounded (typically max 8 hours, escalating after that)
- The operator can document the justification at the moment of shelving
- Supervisor notification is automatic
Case Study — Specialty Chemicals Plant, 12 Units, 18 Months
A mid-Indian specialty chemicals manufacturer running batch and continuous processes across twelve units. Pre-rationalization average alarm rate exceeded 80 per hour per operator across the busiest console. The board approved a full lifecycle program after a near-miss during a compressor trip — the same scenario described at the top of this page.
| KPI | Before | After workshop (Month 6) | After AI layer (Month 18) | EEMUA target |
|---|---|---|---|---|
| Average alarm rate per hour | 82 | 14 | 5.4 | < 6 |
| Peak alarms in 10 min during upset | 247 | 62 | 8 | < 10 |
| Standing alarms at any time | 68 | 11 | 3 | < 5 |
| Chattering alarms | 22 | 3 | 0 | 0 |
| Stale alarms (> 24 hr) | 14 | 2 | 0 | 0 |
| Priority distribution H / M / L | 28 / 41 / 31 | 9 / 22 / 69 | 5 / 16 / 79 | 5 / 15 / 80 |
| Bad-actor top-10 share | 54% | 18% | 6% | < 5% |
| Median response time on High alarms | 27 min | 11 min | 6 min | < 10 min |
What the AI layer added on top of the rationalization
The workshop alone took the plant from 82 alarms per hour to 14 — an 83% reduction. The AI guidance layer over the next twelve months pushed that to 5.4 by catching the cascade patterns that the workshop could not predict, applying state-based prioritization across batch transitions, and flagging the drift candidates before they re-entered the noise floor. The workshop did the cleanup; the AI keeps it clean.
Six-Phase Roadmap from Baseline to Operational AI Layer
A standards-compliant alarm management program does not need to be a two-year project. Six phases, twelve to eighteen months end-to-end, with measurable wins inside the first ninety days. The phases below are sequenced for chemical plants with active production — no shutdown required for any phase.
Baseline Against the Standards Week 1–4
Connect to the DCS alarm historian, run thirty days of measurement against every EEMUA / ISA-18.2 KPI. Identify the bad-actor tags, the flood patterns, the standing and stale lists. Deliver a written gap analysis against the standards.
Quick-Win Engineering on Bad Actors Week 5–10
The Pareto curve is brutally skewed. Engineering the top ten bad-actor tags — deadband adjustment, sensor inspection, timer tuning, removal — typically delivers a 40–60% alarm rate reduction inside six weeks, before any rationalization begins.
Philosophy Document and Workshop Prep Week 11–16
Author or refresh the alarm philosophy. Define priority matrix, classification rules, suppression and shelving governance. Build the master alarm database template. Train rationalization team on the philosophy and the workshop methodology.
Rationalization Workshops by Unit Month 5–9
Unit-by-unit rationalization. Process engineer, operations rep, instrumentation, safety in the room. Walk the candidate list against the philosophy. Document cause-consequence-action in the master alarm database. Output feeds the MOC pipeline.
AI Guidance Layer Deployment Month 10–13
Install the AI layer in parallel with the existing DCS — no control system modification. Predictive suppression learns the cascade signatures over 4–6 weeks. State-based prioritization and adaptive shelving become operational. Pattern-based root cause guidance is the final layer.
Monitoring, MOC, and Audit Cycle Month 14+
Monthly KPI report against EEMUA targets. Quarterly bad-actor review. Annual audit with independent assessment. Every alarm change flows through MOC referencing the philosophy. The lifecycle is now closed-loop.
Alarm Management for Chemical Plants — Operations Questions
Will rationalization expose the plant to regulatory or HAZOP risk?
No, if it is done correctly. Every alarm removal during rationalization is traced back to the philosophy criteria — defined operator action, definable consequence, time to respond. Alarms originating from HAZOP or LOPA studies are flagged as such and cannot be removed without re-opening the corresponding study. The output is a defensible reduction, not a unilateral cut.
How is the AI guidance layer different from a smart alarm system in the DCS?
DCS-native alarm suppression is rule-based and configured by engineering during detailed design. AI guidance is pattern-based and learns the actual cascade signatures of your specific plant from historian data. The two are complementary — DCS suppression handles the documented rules, AI handles the patterns that nobody documented because nobody knew they existed.
Does the AI layer modify or interact with the safety-instrumented system?
No. The AI guidance layer is strictly an advisory and visualization layer over the BPCS alarm stream. It does not write to the DCS, does not interact with the SIS, and does not modify any safety function. Suppression decisions affect only the operator's HMI presentation — the underlying alarm states in the DCS are unchanged and remain available for full audit.
How long before the plant sees a measurable reduction in alarm rate?
Six to ten weeks for the first 40–60% reduction from quick-win bad-actor engineering. Six to nine months for the full workshop-driven rationalization gain. Twelve to eighteen months for the AI layer to mature and the program to reach EEMUA-target performance. Measurable improvement starts in the first quarter.
What is the operator's reaction when alarms start getting cut?
Initial resistance is common — operators have developed coping strategies around the noise and removing it feels destabilising. The philosophy walk-through and the alarm response procedure documentation address this directly. Within three months of going live, the same operators are the strongest advocates for the program. The pattern is universal.
Do we need to buy NVIDIA AI servers separately?
No. The fully-loaded AI server is supplied pre-configured and pre-loaded with the alarm guidance models, historian connectors, philosophy templates, and KPI dashboards. On-premise deployment — no cloud, no data egress, no DCS modification. Rack it, connect power and Ethernet, and the system goes live. Cabling, historian integration, philosophy authoring support, operator training, and 24×7 remote monitoring are all included.
What is the typical timeline from contract to first live KPI dashboard?
Live in 6–12 weeks for the baseline and quick-win phase. Three-phase delivery: weeks 1–4 — historian integration, baseline measurement. Weeks 5–8 — bad-actor engineering, philosophy work. Weeks 9–12 — first rationalization workshops, KPI dashboard go-live. The full lifecycle with AI layer mature reaches steady state by month twelve to eighteen.
Stop the Flood. Restore the Warning.
Hardware + software bundle. Pre-configured NVIDIA AI server, racked and ready, on-premise — no cloud, no data egress, no DCS modification. Pre-loaded with EEMUA 191 / ISA-18.2 / IEC 62682 KPI dashboards, philosophy templates, predictive suppression models, and master alarm database. Cabling, historian integration, philosophy authoring support, operator training, and 24×7 remote monitoring all included. Live in 6–12 weeks. Trusted by 1000+ industrial clients with 99.9% uptime.







