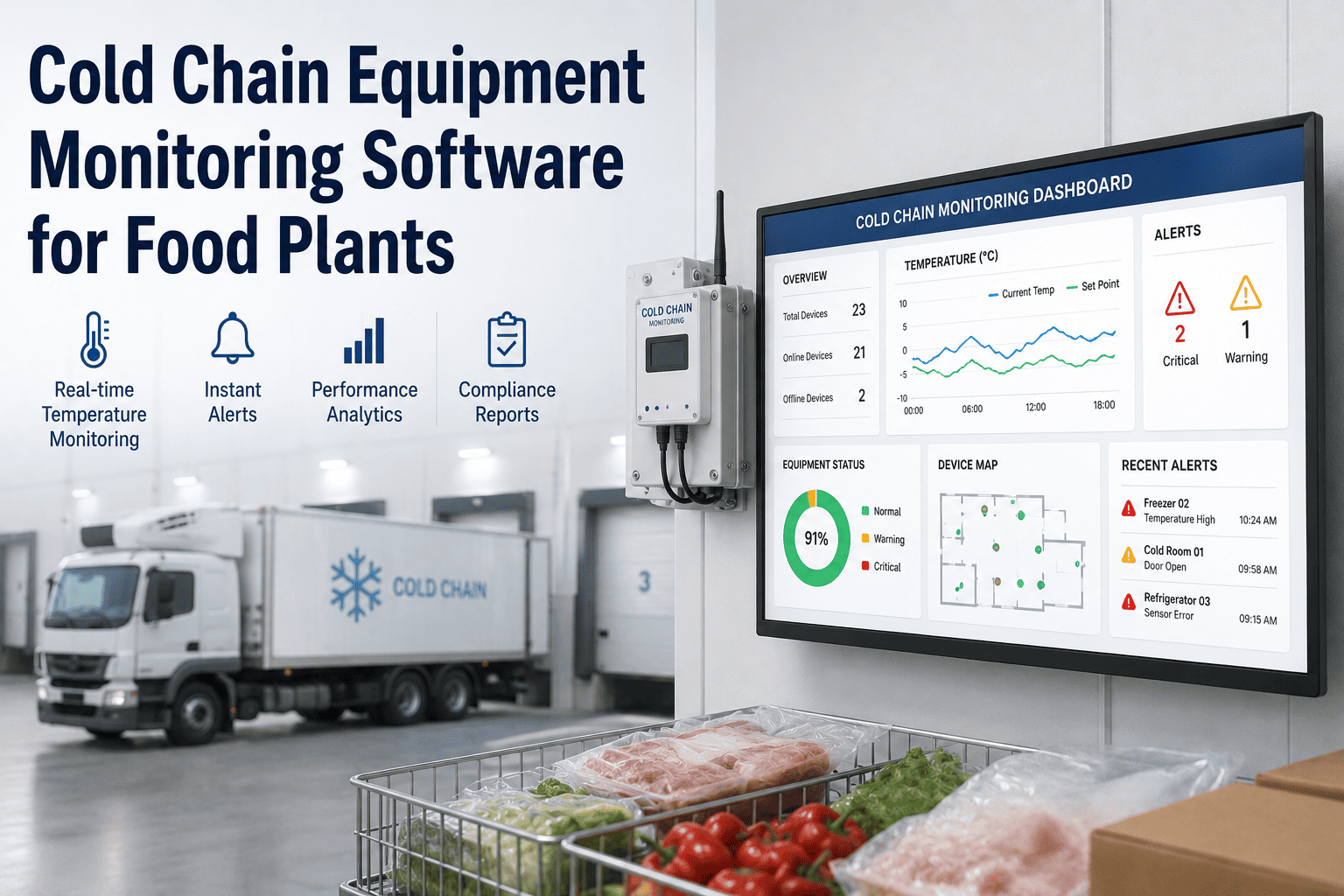
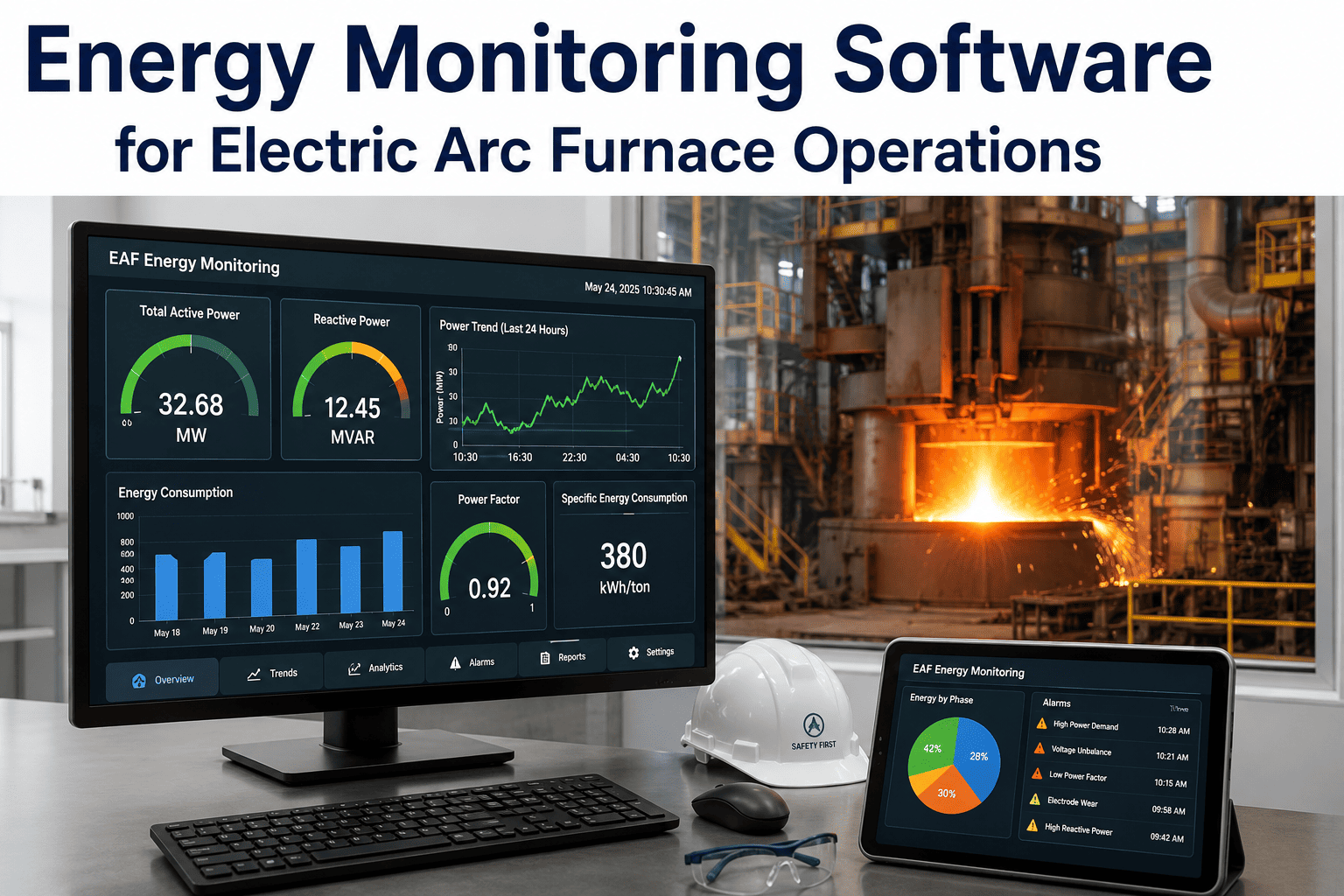
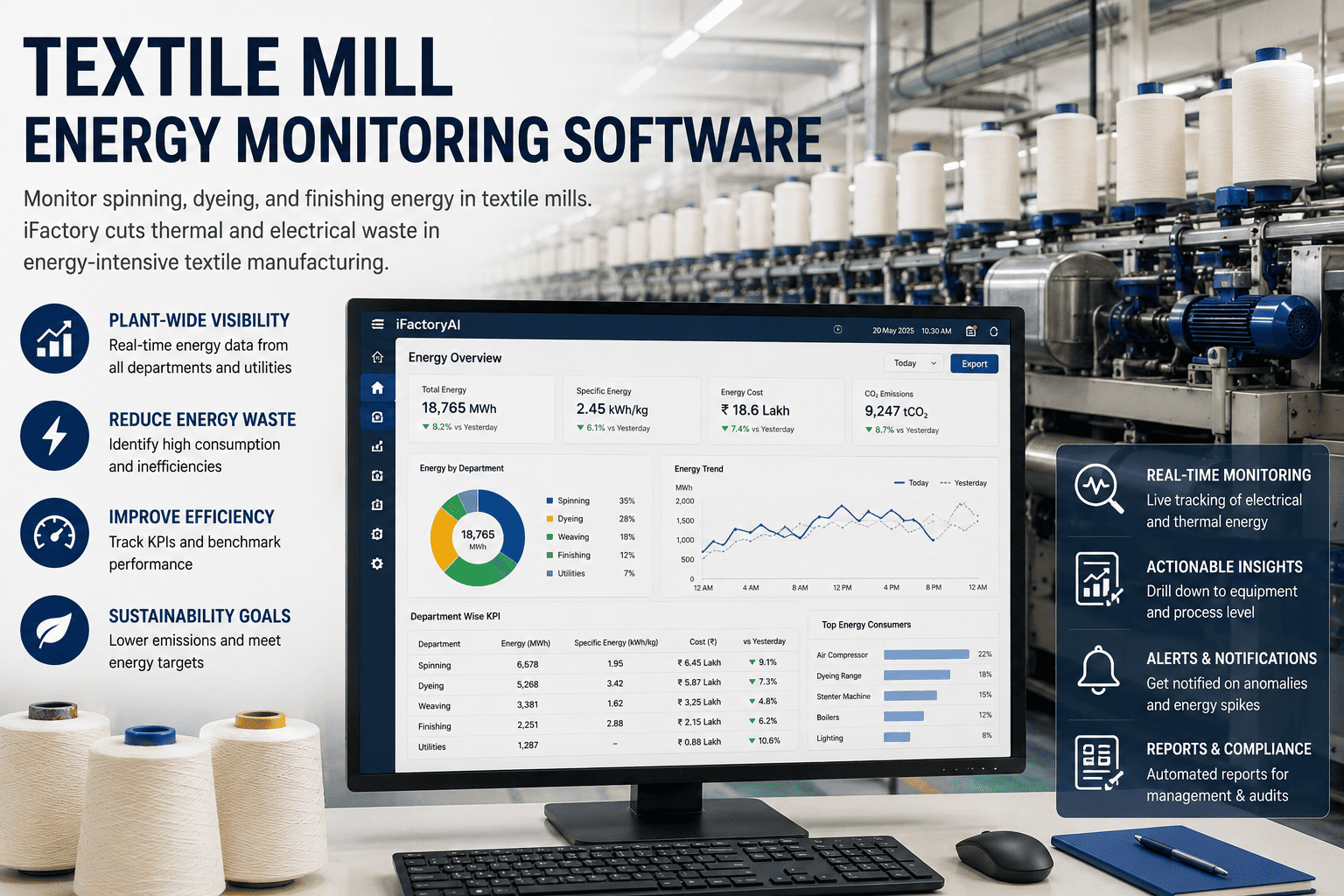
The compressor that drew double its baseline at 2:17 AM is the cost line nobody sees until it shows up on the monthly utility bill — by which point it's done thirty hours of damage. Energy waste doesn't announce itself; it just shows up retroactively in the next invoice. Real-time alerts close that gap. The same signal that becomes a four-figure surprise at month-end becomes a phone notification at 2:18, and an operator either fixes it or makes a deliberate choice not to. An iFactory energy alerts module reads the meters and process signals you already have, applies configurable thresholds and anomaly detection on top, and pushes the notification to whoever owns the asset — app, email, or SMS — in under thirty seconds.
iFactory Energy Monitoring
Real-Time Energy Alerts & Notifications
Energy waste doesn't announce itself — it shows up retroactively in the next invoice. Real-time alerts close that gap. iFactory pushes a configurable, multi-channel notification the moment a spike, threshold breach, or anomaly fires — and routes it to whoever can actually act on it.
< 30s
event to first notification
24/7
continuous, never sleeps
3+
channels: app, email, SMS
4
severity tiers, smart routing
Why Energy Waste Goes Unnoticed for Hours
Most plants discover energy events the same way: in the utility invoice, three weeks after the fact. The compressor drew its overload at two in the morning, the HVAC ran a setpoint chase all weekend, the lighting circuit kept a quarter of the building lit through the holiday — and nobody knew because nobody was looking. Energy monitoring without alerts is bookkeeping. Energy monitoring with alerts is operations. The difference is whether a human gets told in seconds or finds out in weeks.
What the Alert Feed Actually Looks Like
Below is the live alert feed an operator sees on the iFactory mobile app or control-room dashboard. Each alert carries its severity, the asset, the deviation, the channels it went out on, and the status. The same view drives the morning energy review — except the morning review starts from "yesterday's open and resolved alerts" instead of "what happened last week."
Live Alert Feed
Plant 1 + Plant 2 · refreshed live
Compressor #3 power 1.8× baseline
Plant 1 · Utilities · Spike detection
HVAC Zone 4 setpoint exceeded 3h
Plant 1 · Building · Threshold breach
Boiler #2 efficiency dropped 8 pp
Plant 1 · Steam · Anomaly detection
Peak demand within 5% of contract limit
Plant 1 · Electrical · Threshold approach
Lighting circuit 7 anomaly
Plant 2 · Building · Anomaly detection
Three Kinds of Alerts That Cover Almost Every Event
Almost every energy event you'd want to know about fits into one of three patterns. Each one is detected differently, and each one tolerates different sensitivity. Picking the right rule type for each asset is the difference between a useful alert system and one that nobody trusts.
Type 1
Threshold Breach
A signal crosses a static or scheduled limit — peak demand against contract, motor current above nameplate, HVAC zone above setpoint for too long. Simple, deterministic, and the easiest place to start.
Type 2
Spike / Step Change
A signal jumps by a defined percentage or absolute value within a short window — a compressor pulling 1.8× baseline, a steam flow doubling without a load change. Catches the events thresholds miss because the level is still "in band."
Type 3
Anomaly Detection
A signal diverges from its learned normal pattern — a boiler running below typical efficiency, a lighting circuit on outside its usual schedule. Built on baselines, not thresholds; finds the slow drift threshold rules cannot.
Want to see which rule type fits each of your assets? Talk to a specialist and we'll map a starter rule set against your meters.
The Alert Lifecycle, From Sensor to Closure
Every alert moves through the same five stages, and the system tracks each one. The discipline is not in the firing — that's the easy part. It is in the routing, the acknowledgment, and the resolution, with every step time-stamped so the next morning's review knows exactly what happened and how long it took.
1
Detect
Meter or process signal crosses a configured rule. Threshold breach, spike, or anomaly — the trigger is logged with its raw value and time.
2
Classify
Severity assigned automatically based on the rule and the asset — Info, Warning, Critical, or Emergency — and a recipient list resolved.
3
Route
Notification fans out across the channels the severity calls for — app, email, SMS, or voice escalation if no one acks the more urgent tiers.
4
Acknowledge
The recipient takes ownership in one tap. The alert is now owned by a named human, the clock starts on resolution time.
5
Resolve
Root cause addressed or accepted with a note. Alert closes with the resolution time logged for the next morning's review and the monthly trend.
Channel by Severity — Where Each Alert Goes
Not every alert deserves a 3:00 AM phone call. The routing matrix below is what works for almost every site: progressively wider channel coverage as severity rises, so the recipient never has to ask "should I have been called for this?" The mapping is configurable per asset and per shift, but the cascade is the default that holds.
Info
App push
Email
SMS
Voice call
Warning
App push
Email
SMS
Voice call
Critical
App push
Email
SMS
Voice call
Emergency
App push
Email
SMS
Voice call
Want this routing matrix mapped against your on-call roster? Book a demo and we'll wire it to your shift schedule.
How to Avoid the One Thing That Kills Alert Systems
Alert fatigue. It is what makes operators silence the app within a month, route SMS to a number nobody checks, and ignore the email folder entirely. Four practices, applied from day one, are the difference between an alert system that gets used and one that becomes background noise.
Calibrate Thresholds to the Asset
Default thresholds from the OEM are starting points, not finished settings. The first thirty days are tuning — kill false alarms by aligning rules to how the asset actually behaves at this site.
Coalesce Bursts Into Summaries
Fifty alerts in sixty seconds is a system event, not fifty independent problems. Burst coalescence groups them into one notification with the count and the asset, so the operator gets one ping, not fifty.
Match the Channel to the Urgency
Not every event is a 3 AM phone call. Info goes to the app. Warning adds email. SMS is reserved for things the operator actually has to act on now. The discipline keeps every channel trusted.
Auto-Resolve When the Condition Clears
If the spike is gone before anyone acted, the alert closes itself with a logged note. Forcing humans to close alerts that fixed themselves is one of the fastest ways to lose trust in the whole system.
Standing Up an Alerts Program in Four Steps
The fastest way to lose the value of an alert system is to launch it with default rules and hope. The fastest way to capture the value is to follow four steps in order, tune the rules against thirty days of real data, and treat the first month as configuration — not production.
1
Connect the Meters You Already Have
Electric submeters, gas, steam, fuel oil, compressed air. Read-only into the historian. No new instrumentation for the first cut — the rules layer is where the value lands.
2
Configure Starter Rules
Threshold rules on contractual limits, spike rules on the largest motors and compressors, anomaly baselines on HVAC and lighting. Severity assigned to each rule from day one.
3
Define Routing and On-Call
Who gets what, when, on which shift. The routing matrix is the contract — encoded in the system, not in someone's memory. Escalation rules for any alert that goes unacknowledged.
4
Tune for Thirty Days
Treat the first month as tuning. Kill false alarms, surface missed events, coalesce bursts, calibrate thresholds. By day thirty the alert feed is one the operator actually trusts.
Want this thirty-day rollout scoped against your meters and your on-call roster? Talk to a specialist and we'll lay out the rule set.
Frequently Asked Questions
How long from event to notification?
Under thirty seconds end to end for most rules, often well under that. The detection itself runs in seconds against the live meter or process signal. Routing, channel fan-out, and delivery account for the rest. The bottleneck is almost never the system — it's the operator's phone being on silent, which is why multi-channel delivery and escalation rules matter.
Do we need new meters to set this up?
Almost never for the first cut. Most plants already have electric submeters, gas flows, steam meters, and process signals in the historian. The alerts layer reads from what's there and adds the calculations the historian doesn't compute live. New instrumentation is added later, targeted at the blind spots the first month surfaces — usually nowhere meaningful.
How is anomaly detection different from a threshold rule?
Threshold rules compare a value to a fixed or scheduled limit. Anomaly detection compares it to a learned baseline of how the asset actually behaves at this time of day, this shift, this load condition. A boiler can be inside its threshold band and still be anomalous if it's running 8 percentage points below typical efficiency. Threshold catches what's out of bounds; anomaly catches what's drifted.
How do you keep alert fatigue from setting in?
Four practices: calibrate every threshold to the asset, not the OEM default; coalesce bursts so a fifty-event minute becomes one notification with a count; match the channel to the severity so SMS is rare and earned; and auto-resolve alerts that clear themselves before anyone acts. Treat the first thirty days as configuration, not production, and the alert feed becomes one the operator trusts.
Can alerts be tied into existing systems like SCADA or maintenance management?
Yes. Alerts can open a work order in maintenance management automatically for the events that need a fix, push status into SCADA so the control-room view stays current, and feed the daily energy review without manual reconciliation. The alerts layer sits above the existing stack and reads from it — it does not replace what's already validated.
Stop finding waste in the invoice.
See Your First Energy Alert in Under Thirty Days
Bring one site — the one with the highest utility bill or the equipment you most suspect is wasting. We'll connect the meters already on it, configure threshold, spike, and anomaly rules against the assets that matter, wire up the routing to your on-call roster, and run it for thirty days. The alerts that fire in that window will tell you exactly what an always-on, multi-channel notification system is worth on your floor.
30
days, first tuned ruleset
< 30s
event to notification
Multi
channel, severity-aware