Where your AI runs is one of the first architecture decisions a greenfield plant makes, and one of the most expensive to undo. Run a vision model in the cloud and a few hundred milliseconds of round-trip can miss the defect it was meant to catch. Run everything on your own hardware and you are buying, cooling, and babysitting GPU servers. SaaS, on-premises, and hybrid edge each win on different axes — latency, security, data sovereignty, and five-year cost — and the right answer depends less on ideology than on the workload. This guide compares the three for manufacturing AI, so you can place each workload where it belongs.
Choosing where your plant's AI will run? Book a 30-minute deployment architecture consultation to map SaaS, on-prem, and edge to your workloads.
A Spectrum From the Machine to the Cloud
The closer the compute sits to the machine, the lower the latency and the more your data stays in your control. The closer it sits to the cloud, the easier it is to scale and the less hardware you own. Most plants end up using more than one point on this line.
Why Deployment Model Is a Day-One Decision
Manufacturing AI is a different animal from a chatbot or an analytics dashboard. Much of it is real-time — vision systems and control loops that have to respond in milliseconds, not after a round-trip to a distant data center. Much of it runs on sensitive process data that cannot freely leave the site. And it runs continuously, which changes the cost math entirely. Because re-architecting a deployment after the plant is live is painful and costly, the model you pick at design time is one you will live with for years. If you want it scoped against your latency and sovereignty needs, you can map it with an industrial AI specialist.
latency real-time factory AI needs — too fast for a cloud round-trip
GPU utilization above which owning hardware tends to beat renting on cost
of cloud AI spend that data egress fees alone can quietly add
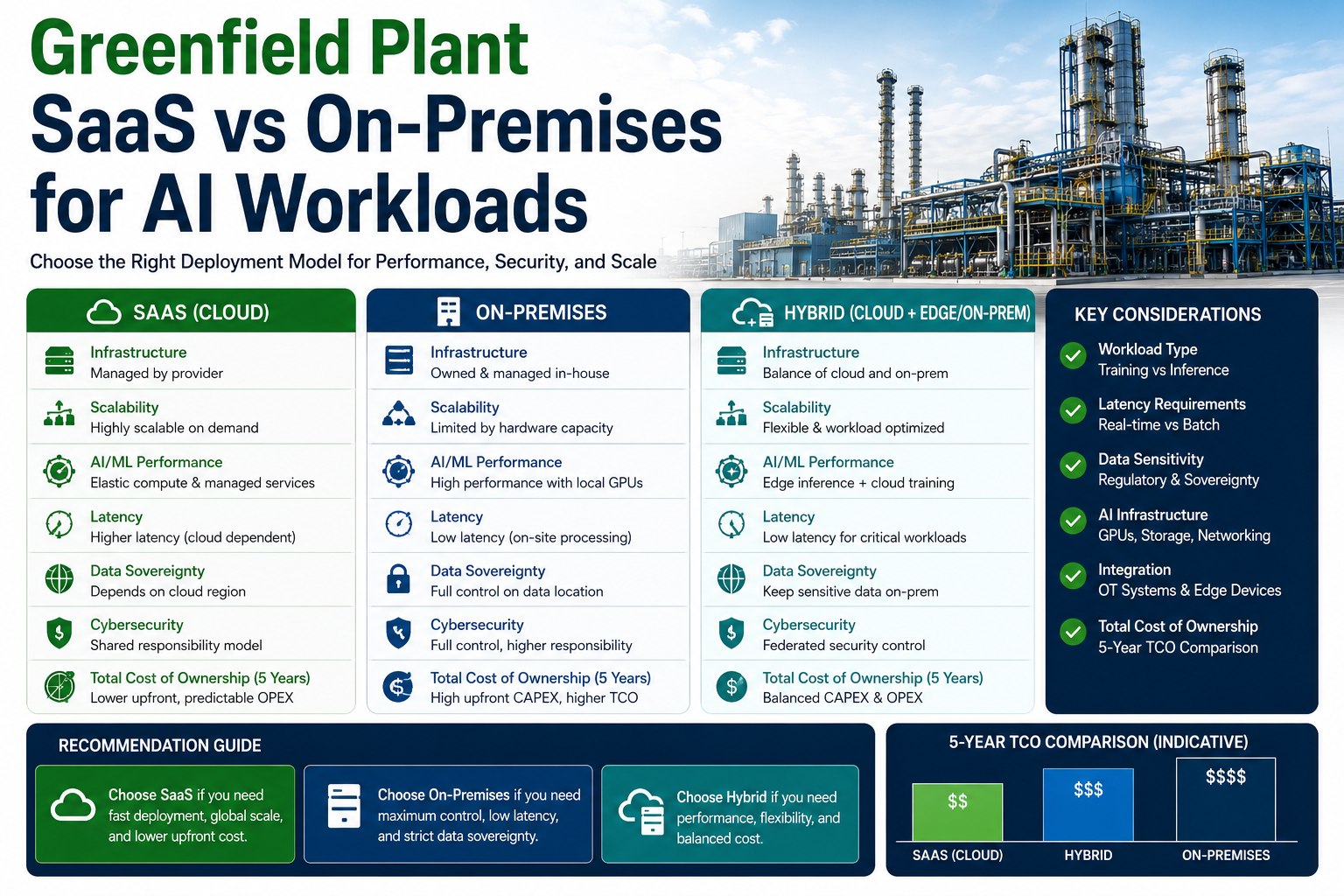
SaaS, On-Premises, and Hybrid: The Three Models
Each model is a different answer to the same question — who owns the hardware, and how close to the machine does the AI run. None is universally right.
SaaS / Cloud
Vendor-hosted and subscription-based, with elastic compute you rent by the hour.
Best for: model training, analytics, and bursty or experimental workloads.
Watch: latency, egress costs, and data leaving your site.
On-Premises / Edge
Runs on your own hardware in the plant, often on small edge nodes at the machine.
Best for: real-time inference, sensitive data, and sustained high-volume work.
Watch: upfront cost, GPU operations, and slower scaling.
Hybrid
Train and burst in the cloud, infer at the edge — each workload placed where it fits.
Best for: most manufacturers, balancing scale against control.
Watch: it needs deliberate architecture and clear workload placement.
Not sure which model fits which workload? Book a workload-placement workshop and we will sort your AI use cases across edge, on-prem, and cloud.
The Decision Factors: Latency, Security, Cost, and Scale
The choice comes down to a handful of factors that pull in different directions. Laid side by side, the trade-offs are clear.
5-Year TCO: Where the Money Actually Goes
Total cost of ownership is where most comparisons go wrong, because each side hides costs the other makes obvious. A real five-year view counts every line, not just the sticker.
Cloud Cost Drivers
GPU-hours or per-token pricing, often well above wholesale
Data egress fees that add 15 to 30% of AI spend
Costs that rise linearly with continuous use
No idle hardware and nothing to maintain
On-Prem Cost Drivers
Hardware capital, amortized over three to five years
Power, cooling, and roughly half to one engineer per cluster
Idle GPUs are expensive, so utilization is everything
Zero egress and zero per-token cost once it is running
The crossover is utilization. Below roughly 70% GPU utilization, the cloud usually wins on cost; above sustained high utilization, owning the hardware pulls ahead. Manufacturing AI runs near-continuously on every machine, which pushes the math toward edge and on-prem — but model your real utilization before you commit.
Want a five-year TCO modeled for your plant? Book a TCO consultation and we will compare cloud, on-prem, and hybrid on your numbers.
Place Every AI Workload Where It Belongs
iFactory is built for the manufacturing profile — edge inference for real-time, low-latency work with data that stays on-site, cloud for training and analytics, and one platform to orchestrate the hybrid in between. Design the right architecture from day one.
Expert Perspective
The framing that traps people is treating this as cloud versus on-prem, as if one has to win. The right question is which workload goes where. Training a model on a year of historical data is a perfect cloud job — bursty, occasional, hungry for compute you only need for a week. Running that model on a vision line at thirty frames a second, on data that legally cannot leave the country, is a perfect edge job — and putting it in the cloud would be both slower and more expensive. Almost every real manufacturer ends up hybrid, not as a compromise but as the correct answer. The mistake is not picking cloud or on-prem; it is picking one for everything, then living with that decision for the life of the plant.
— Industrial AI Practice, iFactory Engineering Team
the split that decides where most workloads should run
of enterprises expected to run hybrid by 2027
staffing each GPU cluster needs — the hidden on-prem cost
The Bottom Line
SaaS, on-premises, and hybrid are not competing ideologies — they are tools for different jobs. Cloud is unbeatable for training, bursts, and experimentation; on-prem and edge are unbeatable for real-time inference, sovereign data, and sustained high-utilization workloads where latency and cost-per-inference decide the outcome. Manufacturing leans toward the edge for its live work and the cloud for its heavy lifting, which is why most plants land on a deliberate hybrid. Decide it at design time, place each workload where its latency, security, and cost profile point, and you avoid the most expensive infrastructure mistake there is — picking one model for everything and paying for it for years.
Design Your Plant's AI Architecture Right
From latency and data-sovereignty requirements to GPU sizing and five-year TCO, iFactory helps greenfield teams place every AI workload across edge, on-prem, and cloud — and runs the hybrid that results on one platform, from day one.
Frequently Asked Questions
SaaS, on-premises, or hybrid — which is best for manufacturing AI?
It depends on the workload, and most manufacturers end up hybrid. Real-time inference for vision and control belongs at the edge or on-premises for low latency and data control, while model training, analytics, and bursty experiments are well suited to the cloud. The pragmatic pattern is to train and burst in the cloud and run live inference at the edge, placing each workload where its latency, sovereignty, and cost profile point.
Why does AI latency matter on the factory floor?
Because many factory AI tasks are real-time. A vision system inspecting parts at line speed, or a model in a control loop, often needs a response in ten milliseconds or less, and a round-trip to a remote cloud data center simply cannot deliver that reliably. Running the model on the edge, next to the machine, keeps latency low enough for the AI to act in time, which is why latency-critical workloads are almost always placed locally.
When is on-premises cheaper than cloud for AI?
When utilization is high and sustained. Cloud pricing scales with use, so for variable or low-utilization workloads it usually wins, but above roughly 70% sustained GPU utilization, owning the hardware tends to cost less over a three-to-five-year horizon once egress and per-token charges are counted. Manufacturing AI often runs near-continuously, which pushes the economics toward on-prem and edge, but the honest answer requires modeling your actual utilization.
Is cloud or on-prem more secure for industrial data?
Neither is automatically more secure, but they distribute responsibility differently. On-premises and edge keep data inside your network and can be air-gapped, which is often required when data sovereignty, residency, or contracts demand it. Cloud providers offer strong certified security under a shared-responsibility model, but the data leaves your environment and depends on secure connectivity. For sensitive process data and IP, many plants keep it local and use the cloud only for non-sensitive work.
How does iFactory support different deployment models?
iFactory is designed for the manufacturing pattern: edge inference for low-latency, sovereign workloads on the plant floor, cloud for training and analytics, and one platform to orchestrate the hybrid in between. Its greenfield advisory helps size the GPU and edge infrastructure and place each workload where it belongs from the start. You can book a consultation to plan it for your facility.







