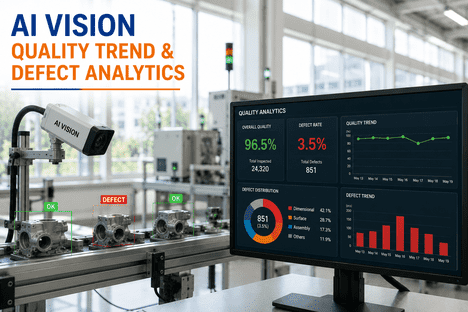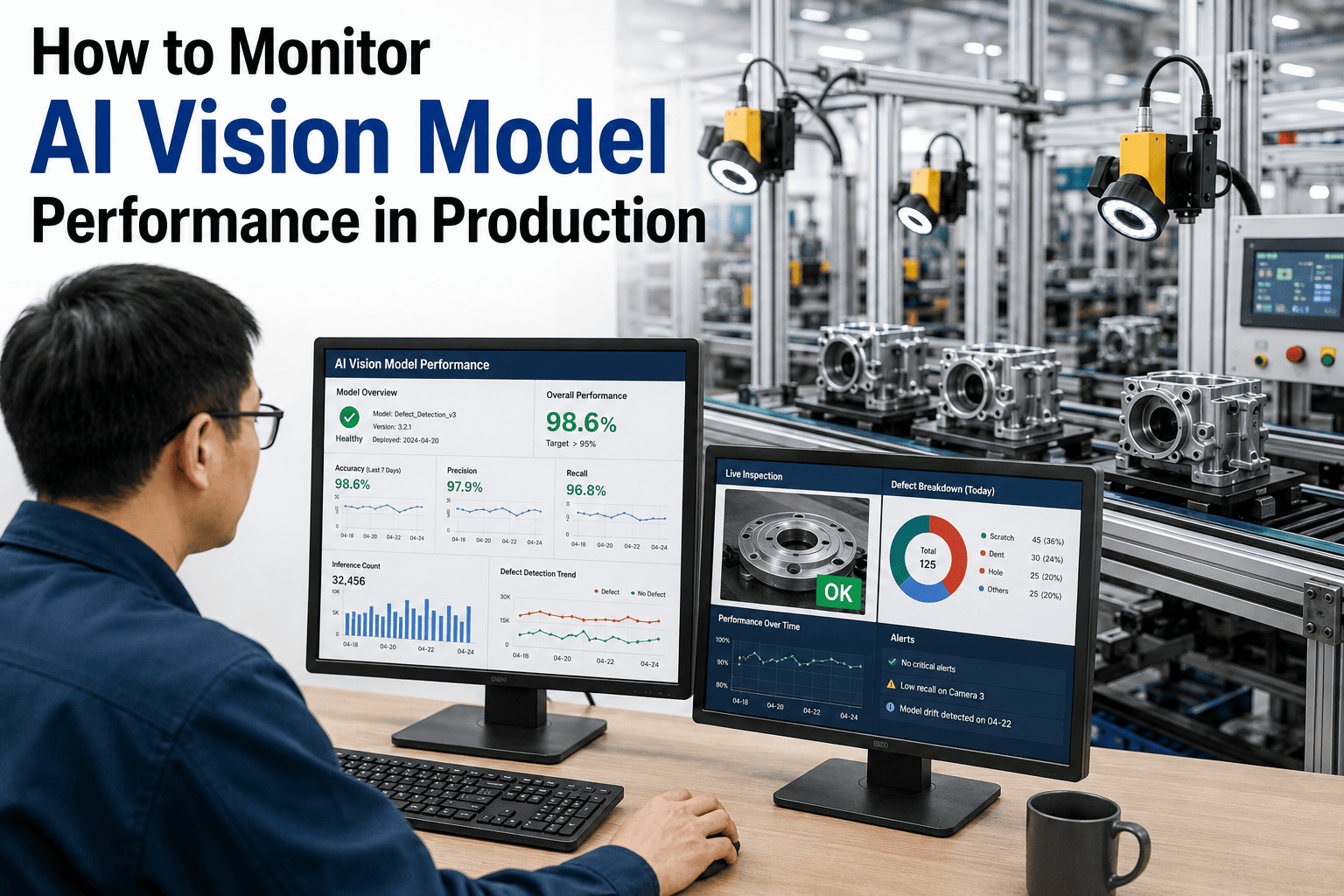
An AI vision model that achieves 99% accuracy during validation does not stay at 99% forever in production. Lighting conditions shift with seasonal ambient light changes, part surface finishes vary between supplier batches, camera lenses accumulate dust and micro-scratches, and the defect population itself evolves as upstream processes drift — all of which silently degrade model performance without generating an obvious error signal. Organizations with mature MLOps pipelines reduce model failure rates by 60% and deploy updates five times faster than teams relying on manual monitoring, according to McKinsey research on industrial AI operations. The difference between an AI vision deployment that delivers sustained value and one that quietly degrades into a false-confidence machine is continuous performance monitoring with automated drift detection and retraining triggers. iFactory's AI vision platform includes production monitoring as a core capability — not an optional add-on — tracking accuracy, precision, recall, false positive rate, and inference latency across every deployed station. Plant engineers ready to see this monitoring architecture demonstrated can Book a Demo with iFactory's MLOps team.
Six Metrics Every AI Vision Deployment Must Track in Production
Production monitoring is not a single accuracy number refreshed weekly — it is a dashboard of interconnected metrics that together reveal whether the model is performing within its validated operating envelope or silently drifting toward a failure mode that will manifest as escaped defects, unnecessary false rejections, or throughput degradation. The following six metrics form the minimum monitoring standard for any AI vision inspection deployment operating at production scale.
Overall percentage of correct classifications — both true positives and true negatives — across all inspected parts. Track daily, weekly, and monthly trends to distinguish short-term noise from sustained degradation. A 2% drop sustained over 5 days is a stronger drift signal than a 5% drop on a single shift that recovers the next day.
Percentage of good parts incorrectly flagged as defective. High false positive rates waste throughput by pulling acceptable parts for unnecessary re-inspection and erode operator trust in the system — leading to manual overrides that defeat the purpose of automated inspection. Monitor per defect class to isolate which classifications are generating spurious alerts.
Percentage of actual defects that the model correctly detects — the metric that directly measures escape risk. A recall drop from 98% to 93% means five additional defects per hundred are escaping to downstream processes or customers. Recall degradation is the highest-priority alert in any quality-critical deployment because it directly translates to increased escape cost.
Time from image capture to classification output — measured in milliseconds. Latency increases can indicate edge compute resource contention, model complexity growth from retraining with larger datasets, or hardware degradation. Sustained latency increases above the cycle time threshold mean the AI system is becoming the production bottleneck rather than the enabler.
Percentage of flagged defects that are actually defective — the complement of false positive rate. Low precision means operators spend time investigating false alarms. Track precision and recall together — optimizing one at the expense of the other creates a system that either misses real defects or cries wolf on good parts, and both failure modes erode production trust.
Distribution of model confidence scores across all predictions — not just the pass/fail threshold. A model producing increasingly clustered confidence scores near the decision boundary is losing discrimination power even if the accuracy metric has not yet dropped. Monitor the median and spread of confidence distributions weekly to detect degradation before it reaches the accuracy metric.
Three Types of Model Drift — and How to Detect Each One
Model drift is not a single phenomenon — it encompasses three distinct types, each with different root causes, detection methods, and remediation approaches. Effective monitoring must distinguish between them because the corrective action is different for each type. Treating all performance degradation as a single retraining trigger wastes resources on problems that retraining cannot fix.
Input Distribution Has Changed
The statistical properties of incoming production images have shifted from the training data distribution — new surface finishes, different lighting conditions, camera degradation, or seasonal ambient light changes. The model's decision boundary was optimized for the training distribution and may no longer fit the current production distribution. Detection uses statistical tests — Kolmogorov-Smirnov test or Population Stability Index — comparing incoming image feature distributions against the training baseline. A PSI reading above 0.2 on critical features triggers a data quality investigation.
The Definition of "Defect" Has Changed
The relationship between image features and defect classification has changed — quality standards have been updated, tolerance windows have been tightened, or a previously acceptable surface condition has been reclassified as a defect by the customer or quality team. The model is correctly detecting what it was trained to detect, but the definition of correct has moved underneath it. Concept drift is detected by monitoring the gap between model predictions and post-inspection quality outcomes — if the model is passing parts that downstream inspection rejects, the concept has drifted.
Output Distribution Has Shifted
The distribution of model outputs — defect rates, class proportions, confidence scores — has changed significantly even if individual predictions appear correct. A sudden shift from 3% to 8% defect detection rate may reflect a real quality change on the line, or it may indicate the model has become oversensitive due to subtle input changes. Prediction drift monitoring compares rolling output distributions against the validated baseline to distinguish real quality events from model instability.
Building the Automated Retraining Pipeline
Manual retraining — someone notices the model is underperforming, collects new data, trains a model on a workstation, manually deploys it, and hopes it performs better — is the MLOps equivalent of reactive maintenance. The automated retraining pipeline replaces this ad hoc process with a structured, trigger-based workflow that detects degradation, collects targeted training data, retrains the model, validates it against the incumbent, and deploys the update — with minimal human intervention and zero production disruption. Operations teams building this capability can Book a Demo to see iFactory's automated pipeline in action.
Drift Detection Trigger
Automated monitoring detects performance drop below defined threshold — accuracy, recall, or false positive rate sustained for three consecutive measurement windows. System initiates the retraining pipeline automatically.
Targeted Data Collection
Active learning identifies the highest-uncertainty images from recent production — the images where the model's confidence was lowest and the classification most likely to be wrong. These images are prioritized for human labeling, minimizing annotation effort while maximizing retraining effectiveness.
Model Retraining
The existing model is fine-tuned on the combined dataset — original training data plus newly labeled production images. Fine-tuning preserves learned features from the original training while adapting to current production conditions. Full retraining from scratch is reserved for cases where concept drift has fundamentally changed the classification target.
Champion-Challenger Validation
The retrained model runs in parallel against the current production model on a validation dataset — the challenger must match or exceed the champion's accuracy, recall, and precision before it is approved for production deployment. If the challenger underperforms, the pipeline logs the result and the current model continues operating.
Automated Deployment with Rollback
Validated model deployed to production through the automated pipeline. Model version registered in the central registry with all training data, hyperparameters, and validation results recorded. Instant rollback to the previous version available if post-deployment monitoring detects unexpected performance changes.
Common Triggers for Production Model Degradation
Understanding what causes models to degrade in production helps teams anticipate and prevent drift rather than reacting after defects escape. The following environmental and operational changes are the most frequent root causes of performance degradation in AI vision inspection deployments — and each is detectable through the monitoring metrics described above.
| Degradation Trigger | Affected Metric | Detection Method | Typical Response |
|---|---|---|---|
| Supplier batch change — new surface finish | Recall drop, confidence shift | Data drift on texture features | Collect 200–500 new images, fine-tune model |
| Seasonal ambient lighting change | False positive increase | Image brightness distribution shift | Adjust lighting or retrain with varied illumination |
| Camera lens contamination | Accuracy drop across all classes | Image sharpness metric degradation | Clean or replace camera lens — not a model issue |
| Quality standard update | Precision/recall mismatch vs downstream | Concept drift detection | Relabel training data to new standards, retrain |
| New product variant introduced | High uncertainty on new variant | Confidence distribution widening | Extend model with new variant training data |
Turnkey Edge Deployment for Production MLOps
iFactory delivers AI vision monitoring and retraining as part of the turnkey hardware-and-software bundle deployed on NVIDIA GPU edge servers — not as a separate MLOps platform requiring its own infrastructure, licensing, and engineering team. The monitoring dashboard, drift detection algorithms, and retraining pipeline run on the same NVIDIA Jetson or L4 edge hardware that processes production inference — live in 6 to 12 weeks following the three-phase deployment roadmap validated across 1,000+ client installations with 99.9% system uptime.
Frequently Asked Questions: AI Vision Model Monitoring
How often should AI vision models be retrained in production?
Retraining frequency should be driven by monitoring data rather than a fixed calendar schedule. Well-monitored models operating on stable production lines may run 6 to 12 months without requiring retraining. Models exposed to frequent supplier changes, seasonal variation, or high product mix may need quarterly updates. iFactory's automated drift detection triggers retraining only when performance metrics cross defined thresholds — eliminating both unnecessary retraining cycles and the risk of operating a degraded model because nobody checked. Teams setting up their monitoring cadence can Book a Demo to see the trigger configuration process.
What causes AI vision model accuracy to degrade over time?
The most common causes are environmental changes that shift the input image distribution away from training conditions — seasonal ambient lighting changes, camera lens contamination, and supplier batch variation in surface finish are the top three. Quality standard updates that change the definition of acceptable versus defective cause concept drift that retraining alone cannot fix without relabeling. New product variants introduced to the line may fall outside the model's training distribution entirely. Each cause produces a different pattern in the monitoring metrics, which is why tracking multiple metrics simultaneously is essential for diagnosing the root cause and selecting the correct remediation.
What is the difference between data drift and concept drift?
Data drift means the input images look different from the training data — different lighting, different surface textures, different backgrounds — but the definition of what constitutes a defect has not changed. The model needs new training examples that reflect current conditions. Concept drift means the definition of defect itself has changed — tighter tolerances, reclassified conditions, new customer requirements — even though the images look the same. The model needs its training labels updated to reflect the new quality standards, not just new images. Distinguishing between the two determines whether the fix is collecting new images or relabeling existing ones, and applying the wrong fix wastes engineering time without resolving the performance issue.
Can monitoring detect hardware issues versus model issues?
Yes. Hardware issues — camera lens contamination, lighting degradation, cable looseness causing image artifacts — produce distinct signatures in the monitoring data. A sudden, uniform accuracy drop across all defect classes on a single station while other stations remain stable points to hardware rather than model degradation. Image quality metrics — sharpness, brightness distribution, contrast — tracked alongside model performance metrics enable automated differentiation between hardware failures requiring maintenance and model drift requiring retraining. Contact iFactory Support for help interpreting monitoring signals on your deployment.
Does iFactory's monitoring require a cloud connection?
No. All monitoring, drift detection, and retraining pipeline components run on the NVIDIA edge hardware deployed at your plant — no cloud connectivity required for any production monitoring function. The monitoring dashboard is accessible via the plant network, and all data remains on-premise. For facilities that operate air-gapped networks due to cybersecurity or regulatory requirements, iFactory's edge-native architecture ensures that monitoring and retraining operate entirely within the plant network boundary without any external data transmission. Optional cloud connectivity is available for multi-site monitoring consolidation if desired.