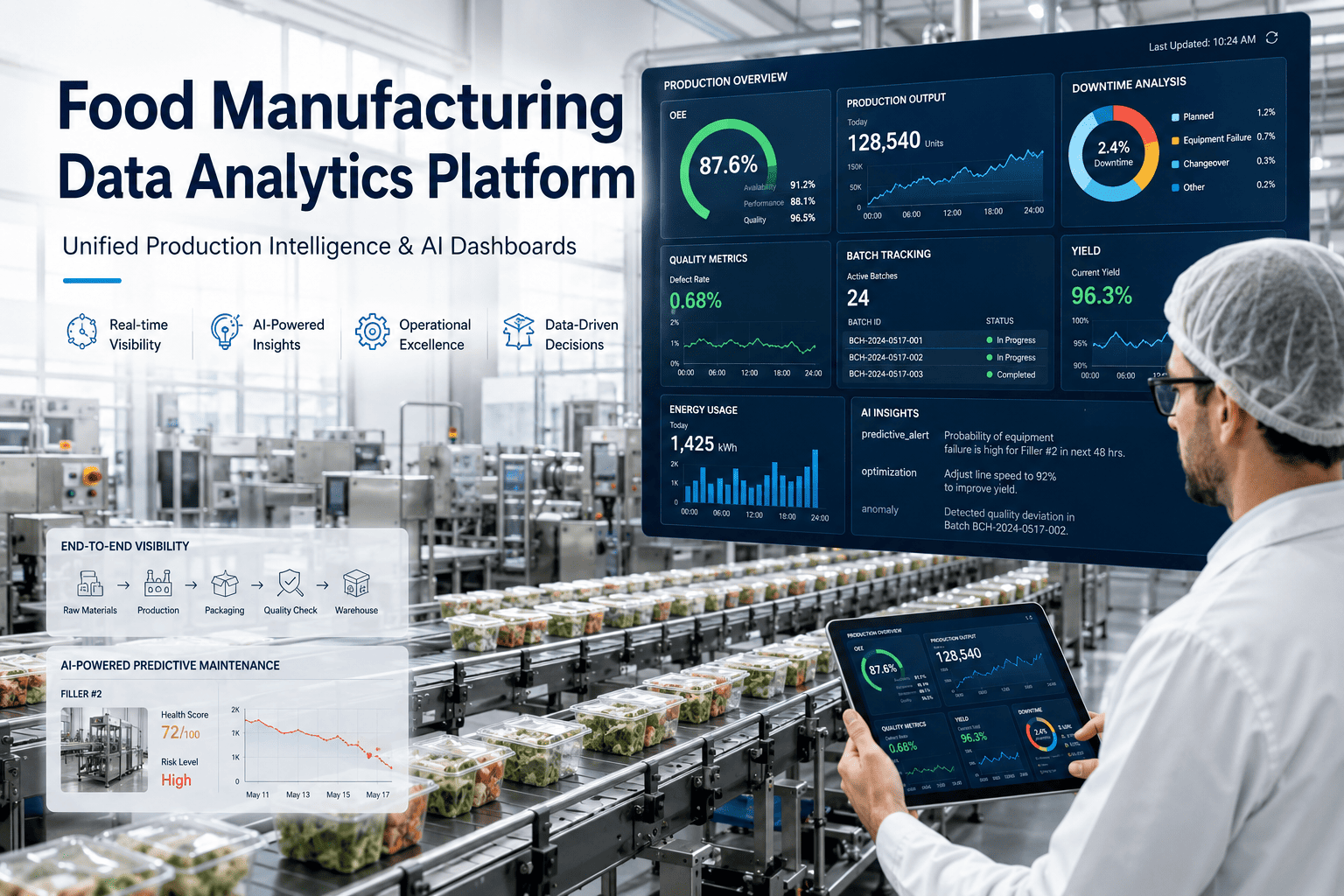
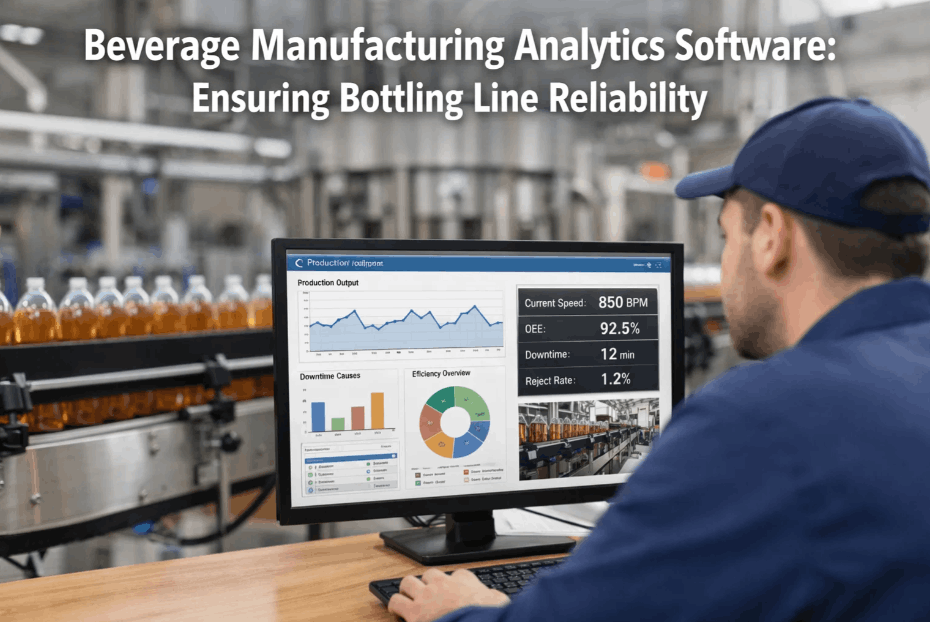
Every food manufacturing plant tracks downtime. Most track OEE. But there is a third metric — analytics response time — that sits between the moment a performance anomaly is detected and the moment your team acts on it, silently compounding losses across every shift. It is the lag between your operational analytics platform flagging a conveyor speed deviation and a technician receiving a dispatched work order. It is the gap between a PLC fault recurrence pattern appearing in your maintenance management software and a supervisor being notified. And in high-throughput food processing environments where a 12-minute unplanned stoppage can cost $18,000 in lost output, that lag is not a process inefficiency — it is a production bottleneck hiding in plain sight.
What Analytics Response Time Actually Measures — and Why It Matters
Analytics response time is the elapsed duration from when a condition monitoring system, SCADA historian, or predictive maintenance software first logs an actionable anomaly to the moment a corrective action is initiated in the field. It is not the same as MTTR — mean time to repair — which measures the repair duration itself. Analytics response time measures the invisible pre-repair window: alert generated -> alert reviewed -> decision made -> technician dispatched. In plants running reactive maintenance workflows, this window routinely stretches to 4–8 hours. In plants with structured technician dispatch software and automated alert escalation, the same window compresses to under 20 minutes. Book a demo to benchmark your current analytics response time against industry peers and see how iFactory closes the gap.
The 5 Stages Where Analytics Response Time Bleeds Production Value
Production bottleneck analysis consistently identifies the same five friction points in food plant alert-to-action workflows. Each stage introduces delay. Each delay translates directly to extended equipment degradation, wider failure windows, and higher repair cost.
Alert Triage Delay
Without priority scoring, technicians spend 15–25 min per alert determining urgency. Platforms that auto-rank alerts by failure probability eliminate this triage cost entirely.
Cross-Shift Handoff Loss
Anomalies in the final two hours of a shift go under-communicated. The incoming shift restarts from zero diagnostic context, extending response time by a full triage cycle.
Disconnected CMMS Data
Technicians receiving work orders without embedded sensor data arrive without a diagnostic hypothesis — re-gathering information the system already captured, adding 20–35 min per incident.
Missing Escalation Triggers
Deferred alerts with no automated re-evaluation escalate silently to failure. Escalation logic re-surfaces deferred items when risk thresholds worsen, forcing action before the window closes.
No Technician Visibility
Manual dispatch via radio adds 10–20 min to every urgent response. Mobile-first dispatch platforms route work orders to the nearest qualified technician automatically.
MTTR Reduction: How Response Time Compression Drives Measurable ROI
MTTR reduction is the most quantifiable outcome of analytics response time improvement — and it has a direct line to OEE score. When the pre-repair window (alert-to-dispatch) is compressed by 60–80%, the total incident duration shrinks even if the actual repair time is unchanged. Book a demo to see how iFactory's MTTR reduction software calculates your plant's current alert-to-action window and models the OEE improvement from closing it. The table below maps typical workflow improvements to measurable MTTR reduction outcomes.
| Workflow Improvement | Mechanism | Avg. Time Saved per Incident | MTTR Impact | OEE Contribution |
|---|---|---|---|---|
| Auto-prioritised alert queues | Eliminates manual triage | 15–25 min | High | +1.5–2.5% |
| Condition data embedded in work orders | Removes on-site diagnostic re-gather | 20–35 min | High | +2.0–3.0% |
| Automated shift handoff alerts | Eliminates cross-shift information loss | 30–60 min | Very High | +2.5–4.0% |
| Mobile technician dispatch | Removes radio dispatch lag | 10–20 min | Medium | +0.8–1.5% |
| Deferred alert escalation rules | Prevents deferred-to-failure events | Full failure avoided | Transformational | +3.0–6.0% |
| Integrated spare parts lookup in CMMS | Eliminates parts confirmation delay | 15–30 min | Medium | +1.0–2.0% |
Operational KPI Dashboards That Make Response Time Visible
You cannot improve what you do not measure — and most food plants do not currently measure analytics response time as a standalone KPI. It sits buried inside MTTR averages, obscured by the noise of repair duration variance. Operational KPI dashboards built for response time visibility separate the alert-to-dispatch interval from the repair duration, exposing the specific stage where time is being lost. Book a demo to see iFactory's live response time KPI dashboard and understand exactly where your plant's workflow is losing minutes on every incident. The four metrics that matter most are mapped below.
Technician Workflow Automation: The Operational Lever Most Plants Underuse
Maintenance teams are not slow because technicians are inefficient — they are slow because the information architecture surrounding technicians is fragmented. A technician managing 12 assets across a 200-metre production floor without mobile work order access, without real-time condition data at the asset, and without a spare parts lookup integration is operating at 40–50% of their capacity on every corrective task. Technician dispatch software that integrates alert context, asset history, required parts, and safety procedure in a single mobile interface eliminates the back-and-forth that inflates repair duration. Book a demo to see iFactory's mobile technician interface in action across a live food plant scenario. Industrial workflow optimization at the technician level is where MTTR reduction software delivers its fastest ROI — typically within 60–90 days of deployment.
Alert Detected and Auto-Scored
The manufacturing execution system or condition monitoring platform detects an anomaly and assigns a risk score based on asset criticality, failure probability, and current production schedule impact. No manual review required for initial prioritisation.
Work Order Auto-Generated with Context
The operational analytics platform creates a pre-populated work order containing the triggering sensor data, asset history, recommended action based on failure pattern matching, and required parts list — all before a supervisor sees the alert.
Nearest Qualified Technician Dispatched
Technician dispatch software identifies the nearest available technician with the correct skill certification for the asset type and pushes the work order to their mobile device with full diagnostic context included.
Resolution Logged and Model Updated
The technician closes the work order with fault findings on mobile. The reliability engineering software ingests this feedback, updates the failure model, and refines future alert scoring accuracy for the same asset class across the facility.
Building a Business Case for Analytics Response Time Investment
The ROI model for reducing analytics response time is more concrete than most predictive maintenance investments because the savings are calculable from existing plant data. Take the last 10 unplanned downtime incidents. For each, identify the timestamp of the first logged anomaly against the timestamp of the first corrective action. The gap between these two timestamps is your current analytics response window — and every minute inside that window has a known cost based on your plant's throughput rate. Plants running this calculation typically find that 35–55% of their total downtime cost sits inside the alert-to-action window rather than the repair window itself. Downtime reduction software that compresses this interval delivers returns that are predictable, auditable, and defensible in capital budget submissions.
Frequently Asked Questions: Analytics Response Time and Downtime Reduction
What is analytics response time and how is it different from MTTR?
MTTR measures repair duration from technician arrival to service restoration. Analytics response time measures the pre-repair window — from anomaly detection to technician dispatch. In most food plants, this invisible gap accounts for 35–55% of total downtime duration yet receives the least optimization attention.
How does technician dispatch software reduce production line bottlenecks?
Dispatch software automatically routes prioritised work orders to the nearest qualified technician with full diagnostic context embedded — removing 3–5 manual steps per event. Plants consistently cut dispatch lag by 60–75% compared to manual radio-based scheduling workflows.
Can existing plant systems measure analytics response time without new software?
If your CMMS and condition monitoring system both log timestamps, you can calculate response time manually — but it is labour-intensive and inconsistent across shifts. Operational analytics platforms automate this measurement continuously across all assets in real time.
Which assets in food manufacturing have the highest analytics response time ROI?
Assets with high failure cost and continuous operation requirements deliver the best ROI: aseptic fillers, homogenisers, CIP pumps, packaging line drives, and compressors. These combine high throughput impact on failure with clear anomaly patterns that give valuable early warning time.
How long does it take to implement workflow automation for maintenance dispatch?
Basic alert routing deploys within 2–4 weeks using existing SCADA and CMMS connections. Full mobile dispatch with escalation rules takes 6–10 weeks for a mid-size facility. Most plants see measurable MTTR reduction within 30–45 days of go-live.